Models and Providers
ZenMux uses a multi-model, multi-provider redundant architecture to ensure the high availability and stability of large language model services. We aggregate top-tier LLMs from across the industry, giving developers a rich selection and flexible usage experience.
Model Catalog
Quick View
On the website's Models page, you can view all supported models and their basic information. Use the filters on the left, the search box at the top, and the sorting options to quickly locate the model you need.
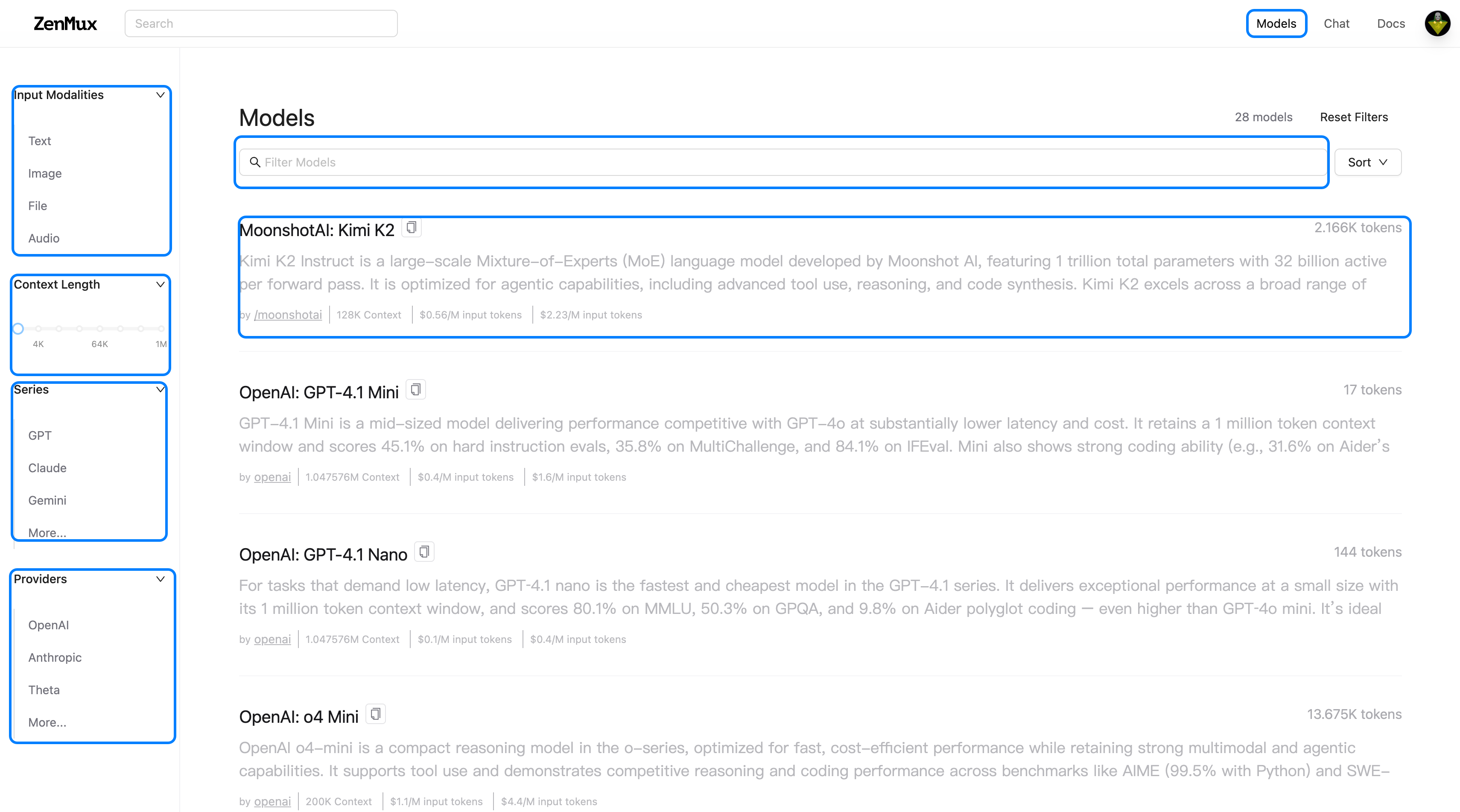
Multi-Provider Architecture
Redundancy and Failover
Most large language models are integrated with multiple providers. If a provider experiences a service incident, ZenMux automatically switches to other available providers to ensure service continuity.
For details on provider routing strategies, see the Provider Routing documentation
Provider Details
Using the anthropic/claude-sonnet-4 model as an example, click the model card to view detailed information:
Supported Providers:
- Anthropic - Native official API
- Vertex AI - Google Cloud managed service
- Amazon Bedrock - AWS managed service
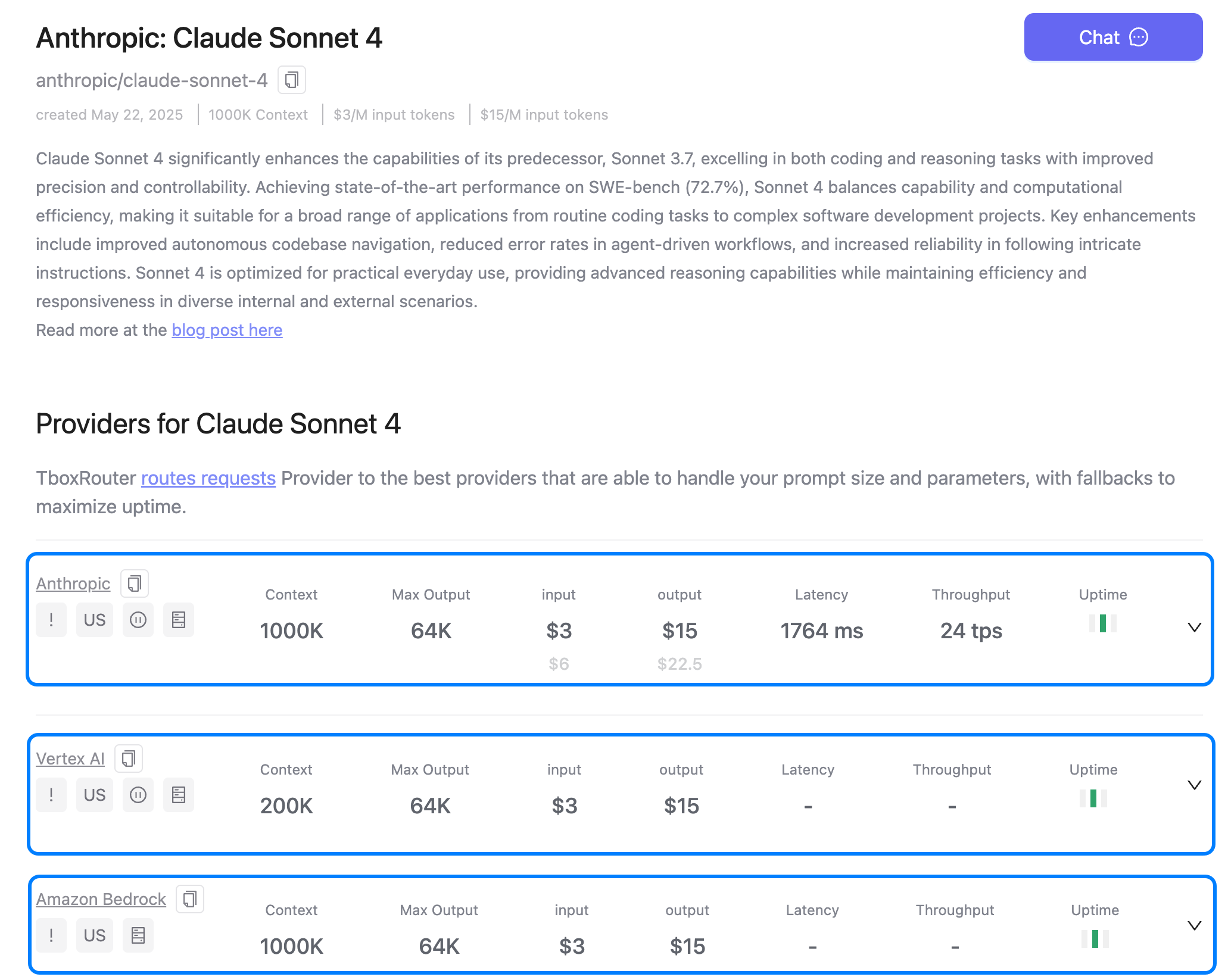
Provider Comparison
On the model details page, you can compare providers across performance metrics, pricing, availability, and more.
Performance Metrics
| Metric | Description |
|---|---|
| Latency (Time to First Token) | Time from the request to the first token |
| Throughput | Number of tokens processed per minute |
| Uptime | Real-time service status and stability |