模型兜底机制
模型兜底(Fallback)是 ZenMux 的容错保障机制,当主要模型或路由策略失败时,自动切换到备用模型继续处理请求。这确保您的应用始终能够获得响应,最大程度降低服务中断的风险。
高可用性保障
兜底机制像安全网一样,确保即使在模型故障、配额限制或网络波动等异常情况下,您的应用依然能够正常运行。
为什么需要兜底机制
在生产环境中,模型服务可能遇到各种不可预期的问题:
- 模型服务故障:上游 API 临时不可用或响应超时
- 性能波动:模型负载过高导致响应缓慢或失败
- 路由失败:智能路由选择的所有候选模型都不可用
兜底机制通过提供可靠的备用方案,确保您的应用始终保持可用性。
核心优势
| 优势特性 | 说明 |
|---|---|
| 高可用性 | 自动容错,确保服务连续性,降低故障影响 |
| 透明切换 | 无需业务代码处理异常,系统自动完成模型切换 |
| 灵活配置 | 支持请求级和全局级配置,适应不同业务场景 |
| 成本优化 | 可指定性价比更高的模型作为兜底,控制应急成本 |
| 统一管理 | 全局配置一次设置,所有请求自动生效,简化维护 |
全局兜底模型配置
ZenMux 支持在控制台后台设置全局的兜底模型,所有请求在失败时自动使用该模型作为备用方案。
配置方式
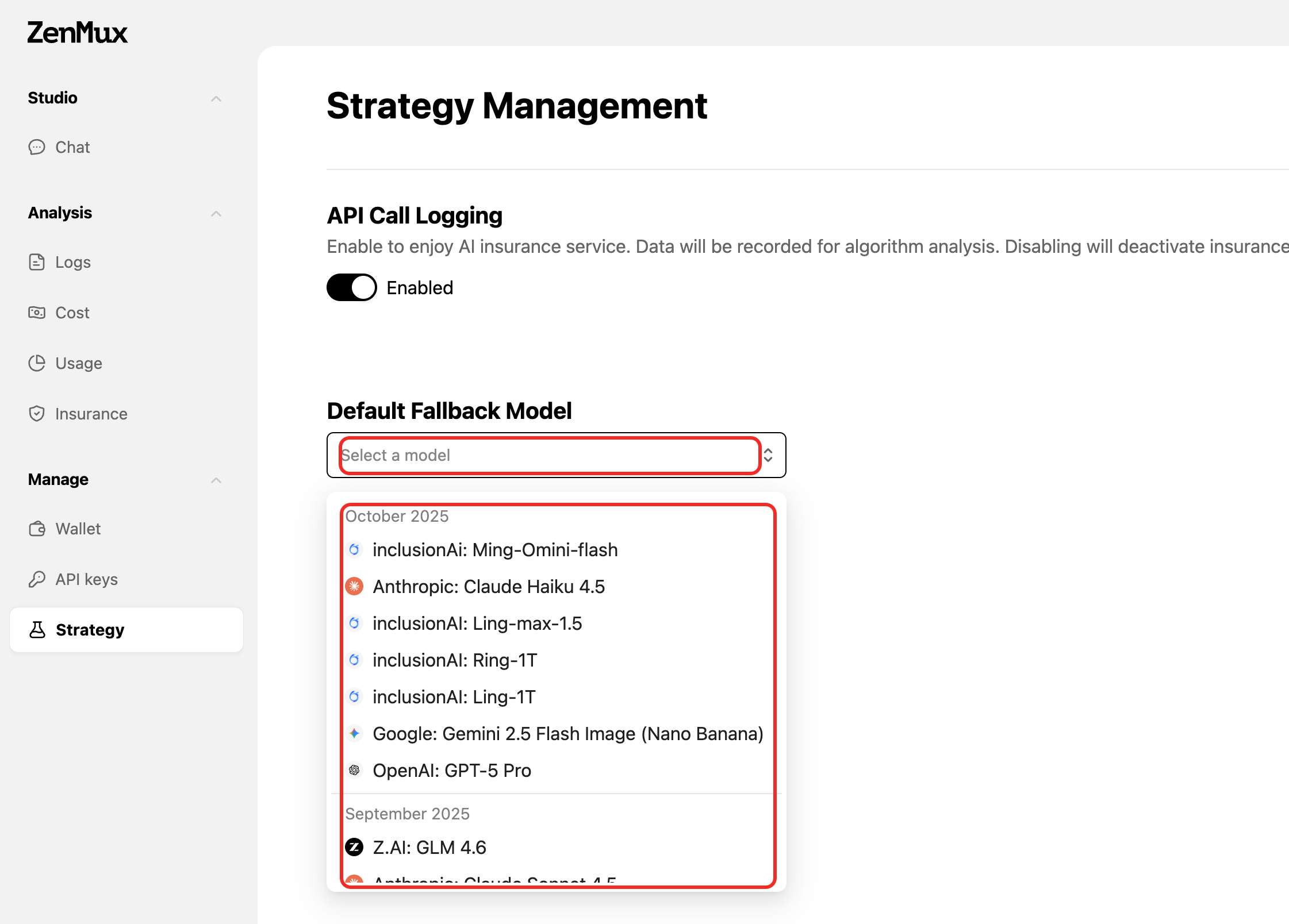
- 访问 ZenMux 策略设置页面
- 找到 Default Fallback Model 配置项
- 从下拉列表中选择您的全局兜底模型
- 保存设置后立即生效
全局配置的优势
- 无需修改代码:一次设置,全局生效,无需在每个请求中重复配置
- 统一管理:集中管理兜底策略,便于调整和监控
- 简化维护:降低代码复杂度,减少配置错误的可能性
- 灵活覆盖:请求级别的兜底配置优先级更高,可根据特定场景覆盖全局设置
请求级兜底配置
对于特定的业务场景,您可以在单个请求中指定兜底模型,覆盖全局配置。
基础用法
通过 provider.fallback 参数指定兜底模型:
{
"model": "anthropic/claude-sonnet-4",
"messages": [
{
"role": "user",
"content": "解释一下什么是量子计算"
}
],
"provider": {
"fallback": "google/gemini-2.5-flash-lite"
}
}from openai import OpenAI
client = OpenAI(
base_url="https://zenmux.ai/api/v1",
api_key="<你的 ZENMUX_API_KEY>"
)
response = client.chat.completions.create(
model="anthropic/claude-sonnet-4",
extra_body={
"provider": {
"fallback": "google/gemini-2.5-flash-lite"
}
},
messages=[
{"role": "user", "content": "解释一下什么是量子计算"}
]
)
print(f"使用的模型: {response.model}")
print(f"回答: {response.choices[0].message.content}")与智能路由配合使用
兜底机制可以与智能路由配合使用,当路由选择的所有候选模型都失败时,自动切换到兜底模型:
{
"model": "zenmux/auto",
"model_routing_config": {
"available_models": ["anthropic/claude-4-sonnet", "openai/gpt-5"],
"preference": "balanced"
},
"provider": {
"fallback": "google/gemini-2.5-flash-lite"
},
"messages": [
{
"role": "user",
"content": "解释一下什么是量子计算"
}
]
}from openai import OpenAI
client = OpenAI(
base_url="https://zenmux.ai/api/v1",
api_key="<你的 ZENMUX_API_KEY>"
)
response = client.chat.completions.create(
model="zenmux/auto",
extra_body={
"model_routing_config": {
"available_models": [
"anthropic/claude-4-sonnet",
"openai/gpt-5"
],
"preference": "balanced"
},
"provider": {
"fallback": "google/gemini-2.5-flash-lite"
}
},
messages=[
{"role": "user", "content": "解释一下什么是量子计算"}
]
)与供应商路由配合使用
兜底机制可以与供应商路由配合使用,当指定的供应商列表都失败时,自动切换到兜底模型:
{
"model": "anthropic/claude-sonnet-4",
"provider": {
"routing": {
"type": "order",
"providers": [
"anthropic/anthropic_endpoint",
"google-vertex/VertexAIAnthropic"
]
},
"fallback": "google/gemini-2.5-flash-lite"
},
"messages": [
{
"role": "user",
"content": "解释一下什么是量子计算"
}
]
}from openai import OpenAI
client = OpenAI(
base_url="https://zenmux.ai/api/v1",
api_key="<你的 ZENMUX_API_KEY>"
)
response = client.chat.completions.create(
model="anthropic/claude-sonnet-4",
extra_body={
"provider": {
"routing": {
"type": "order",
"providers": [
"anthropic/anthropic_endpoint",
"google-vertex/VertexAIAnthropic"
]
},
"fallback": "google/gemini-2.5-flash-lite"
}
},
messages=[
{"role": "user", "content": "解释一下什么是量子计算"}
]
)工作原理
兜底触发条件
系统在以下情况下会触发兜底机制:
- 主模型不可用:上游 API 返回 5xx 错误(Service unavailable errors 502/503)或超时(Model response timeout)
- 认证失败:API 密钥无效或权限不足(401/403 错误)
- 速率限制:达到模型服务的请求频率限制(Rate limit reached)
- 模型不存在:请求的模型标识符无效(404 错误)
- 服务临时故障:主模型服务暂时不可用(Primary model service temporarily down)
- 路由全部失败:智能路由的所有候选模型均不可用
兜底执行流程
- 主模型请求:首先尝试使用指定的主模型或路由选择的模型
- 错误检测:监控请求是否触发兜底条件
- 自动切换:满足条件时立即切换到兜底模型
- 重试请求:使用相同的参数向兜底模型发起请求
- 返回结果:在响应的
model字段标注实际使用的模型
优先级规则
当同时存在多种配置时,优先级从高到低为:
- 请求级
provider.fallback:单个请求中指定的兜底模型 - 全局 Default Fallback Model:控制台设置的全局兜底模型
- 无兜底:如果都未配置,失败时直接返回错误
注意事项
- 兜底模型本身失败时,系统会返回错误,不会进行二次兜底
- 兜底切换会在响应中标注实际使用的模型,便于监控和分析
最佳实践
1. 优先使用全局配置
对于大多数应用场景,推荐使用全局兜底配置:
✅ 推荐做法:
- 在控制台设置全局兜底模型,简化代码维护
- 选择稳定性高、性价比好的模型作为全局兜底
- 定期检查兜底模型的触发频率,优化主模型配置
❌ 避免:
- 在每个请求中重复配置相同的兜底模型
- 选择昂贵的旗舰模型作为兜底(增加应急成本)
2. 特殊场景使用请求级配置
仅在需要差异化处理时使用请求级配置:
# 关键业务:使用高质量模型兜底
critical_response = client.chat.completions.create(
model="anthropic/claude-4-sonnet",
extra_body={
"provider": {
"fallback": "openai/gpt-5" # 高质量兜底
}
},
messages=[...]
)
# 普通业务:依赖全局配置的经济型兜底
normal_response = client.chat.completions.create(
model="anthropic/claude-4-sonnet",
messages=[...] # 使用全局兜底配置
)3. 监控兜底触发情况
通过响应的 model 字段或控制台日志,监控兜底触发频率:
response = client.chat.completions.create(
model="anthropic/claude-sonnet-4",
extra_body={
"provider": {"fallback": "google/gemini-2.5-flash-lite"}
},
messages=[...]
)
# 检查是否触发兜底
if response.model != "anthropic/claude-sonnet-4":
print(f"警告:触发兜底机制,实际使用模型: {response.model}")持续优化
如果发现兜底触发频率过高,应考虑:
- 检查主模型的 API 密钥配置是否正确
- 评估主模型的配额和速率限制设置
- 考虑调整智能路由的候选模型池
- 联系技术支持排查潜在问题
常见问题
Q: 兜底机制会增加请求延迟吗?
A: 只有在主模型失败时才会触发兜底,正常情况下不会影响性能。一旦触发,切换到兜底模型通常在几秒内完成,具体延迟取决于主模型的超时时间和兜底模型的响应速度。
Q: 兜底模型可以设置多个吗?
A: 当前只支持设置一个兜底模型。如果兜底模型本身失败,系统会返回错误。建议选择稳定性高的模型作为兜底。
Q: 如何知道请求是否使用了兜底模型?
A: 响应中的 model 字段会显示实际使用的模型。如果与请求中指定的模型不同,说明触发了兜底机制。您也可以在 ZenMux 控制台 查看详细的请求日志。
Q: 全局兜底配置和请求级配置可以同时使用吗?
A: 可以。请求级配置的优先级更高,会覆盖全局配置。这样可以在大部分场景使用全局配置,同时为特定请求设置差异化的兜底策略。
联系我们
如果您在使用过程中遇到任何问题,或有任何建议和反馈,欢迎通过以下方式联系我们:
- 官方网站:https://zenmux.ai
- 技术支持邮箱:[email protected]
- 商务合作邮箱:[email protected]
- Twitter:@ZenMuxAI
- Discord 社区:http://discord.gg/vHZZzj84Bm
更多联系方式和详细信息,请访问我们的联系我们页面。