Fallback Mechanism
Model fallback is ZenMux’s fault-tolerance safeguard. When the primary model or routing strategy fails, the system automatically switches to a backup model to continue processing the request. This ensures your application consistently receives responses and minimizes the risk of service interruptions.
High Availability Assurance
The fallback mechanism acts like a safety net, ensuring your application continues to operate even in abnormal conditions such as model failures, quota limits, or network fluctuations.
Why You Need a Fallback Mechanism
In production environments, model services may encounter various unexpected issues:
- Model service failures: Upstream APIs may be temporarily unavailable or time out
- Performance fluctuations: High model load can lead to slow or failed responses
- Routing failures: All candidate models selected by intelligent routing are unavailable
Fallback provides a reliable backup plan to ensure your application remains available.
Key Benefits
| Benefit | Description |
|---|---|
| High availability | Automatic fault-tolerance ensures service continuity |
| Transparent switch | No need to handle exceptions in business code; automatic model switching |
| Flexible config | Supports per-request and global configurations |
| Cost optimization | Choose a cost-effective fallback model to control emergency costs |
| Unified management | Configure once globally; all requests inherit, simplifying maintenance |
Global Fallback Model Configuration
ZenMux supports configuring a global fallback model in the console. All requests will automatically use this model as a backup when failures occur.
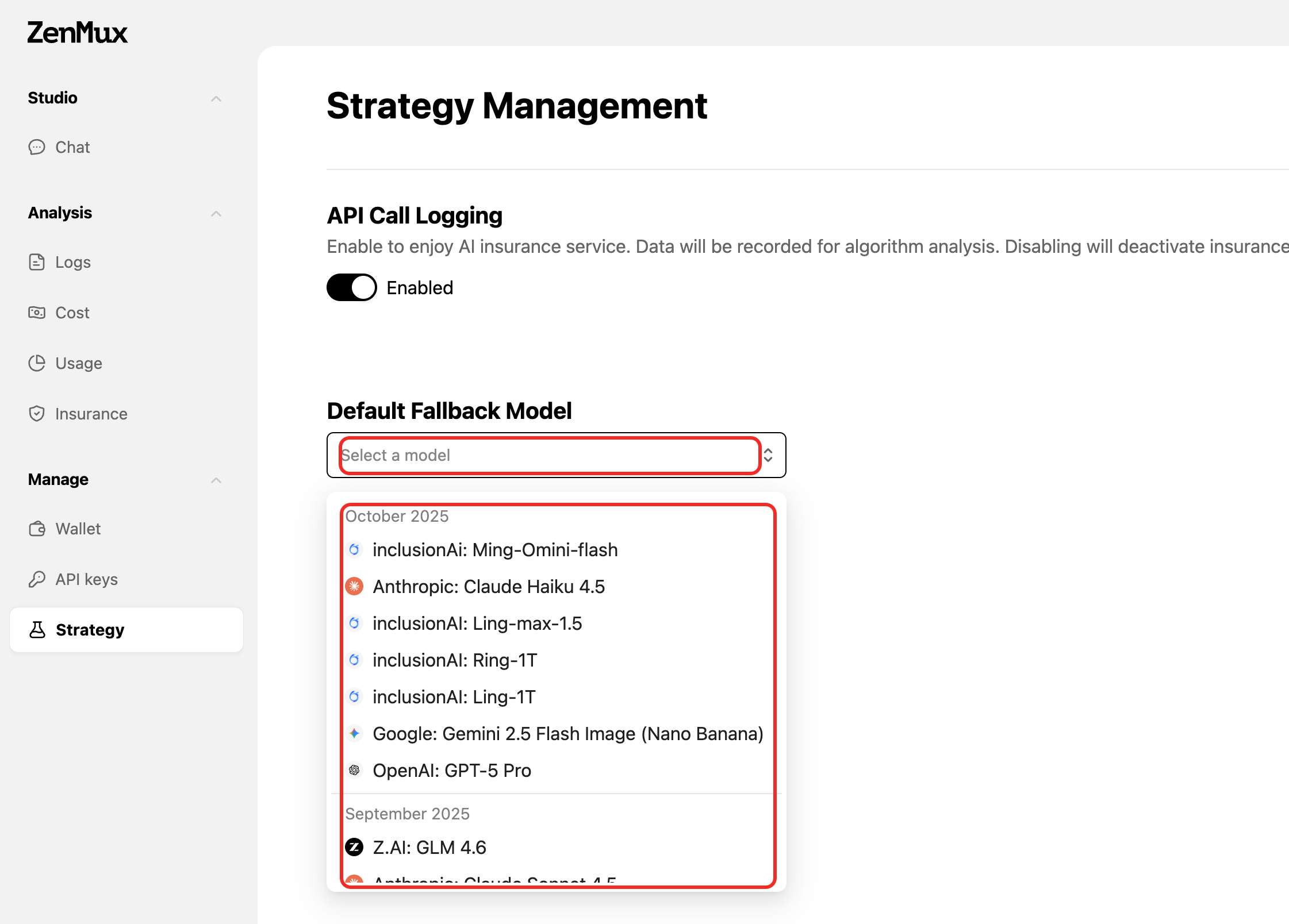
How to Configure
- Visit the ZenMux Strategy Settings page
- Find the Default Fallback Model setting
- Select your global fallback model from the dropdown list
- Save the settings; they take effect immediately
Advantages of Global Configuration
- No code changes: Configure once and apply globally; no need to repeat per request
- Unified management: Centralized control of fallback strategy for easy adjustments and monitoring
- Simplified maintenance: Reduces code complexity and lowers the chance of configuration errors
- Flexible override: Per-request fallback configuration has higher priority and can override the global setting for specific scenarios
Per-Request Fallback Configuration
For specific business scenarios, you can specify a fallback model within a single request to override the global configuration.
Basic Usage
Specify the fallback model using the provider.fallback parameter:
{
"model": "anthropic/claude-sonnet-4",
"messages": [
{
"role": "user",
"content": "Explain what quantum computing is"
}
],
"provider": {
"fallback": "google/gemini-2.5-flash-lite"
}
}from openai import OpenAI
client = OpenAI(
base_url="https://zenmux.ai/api/v1",
api_key="<your ZENMUX_API_KEY>"
)
response = client.chat.completions.create(
model="anthropic/claude-sonnet-4",
extra_body={
"provider": {
"fallback": "google/gemini-2.5-flash-lite"
}
},
messages=[
{"role": "user", "content": "Explain what quantum computing is"}
]
)
print(f"Used model: {response.model}")
print(f"Answer: {response.choices[0].message.content}")Using with Intelligent Routing
The fallback mechanism can be used with intelligent routing. If all candidate models selected by routing fail, the system automatically switches to the fallback model:
{
"model": "zenmux/auto",
"model_routing_config": {
"available_models": ["anthropic/claude-4-sonnet", "openai/gpt-5"],
"preference": "balanced"
},
"provider": {
"fallback": "google/gemini-2.5-flash-lite"
},
"messages": [
{
"role": "user",
"content": "Explain what quantum computing is"
}
]
}from openai import OpenAI
client = OpenAI(
base_url="https://zenmux.ai/api/v1",
api_key="<your ZENMUX_API_KEY>"
)
response = client.chat.completions.create(
model="zenmux/auto",
extra_body={
"model_routing_config": {
"available_models": [
"anthropic/claude-4-sonnet",
"openai/gpt-5"
],
"preference": "balanced"
},
"provider": {
"fallback": "google/gemini-2.5-flash-lite"
}
},
messages=[
{"role": "user", "content": "Explain what quantum computing is"}
]
)Using with Provider Routing
The fallback mechanism can be used with provider routing. If all specified providers fail, the system automatically switches to the fallback model:
{
"model": "anthropic/claude-sonnet-4",
"provider": {
"routing": {
"type": "order",
"providers": {
"anthropic/anthropic_endpoint",
"google-vertex/VertexAIAnthropic"
}
},
"fallback": "google/gemini-2.5-flash-lite"
},
"messages": [
{
"role": "user",
"content": "Explain what quantum computing is"
}
]
}from openai import OpenAI
client = OpenAI(
base_url="https://zenmux.ai/api/v1",
api_key="<your ZENMUX_API_KEY>"
)
response = client.chat.completions.create(
model="anthropic/claude-sonnet-4",
extra_body={
"provider": {
"routing": {
"type": "order",
"providers": [
"anthropic/anthropic_endpoint",
"google-vertex/VertexAIAnthropic"
]
},
"fallback": "google/gemini-2.5-flash-lite"
}
},
messages=[
{"role": "user", "content": "Explain what quantum computing is"}
]
)How It Works
Fallback Trigger Conditions
The system triggers the fallback mechanism in the following cases:
- Primary model unavailable: Upstream API returns 5xx errors (Service unavailable errors 502/503) or times out (Model response timeout)
- Authentication failure: Invalid API key or insufficient permissions (401/403 errors)
- Rate limiting: Request frequency limit reached for the model service (Rate limit reached)
- Model not found: Invalid model identifier (404 error)
- Temporary service failure: Primary model service temporarily unavailable (Primary model service temporarily down)
- Routing completely failed: All candidate models in intelligent routing are unavailable
Fallback Execution Flow
- Primary model request: Attempt using the specified primary model or the model selected by routing
- Error detection: Monitor whether the request meets fallback conditions
- Automatic switch: Immediately switch to the fallback model when conditions are met
- Retry request: Reissue the request to the fallback model with the same parameters
- Return result: The actual model used is indicated in the model field of the response
Priority Rules
When multiple configurations exist, the priority from high to low is:
- Per-request provider.fallback: Fallback model specified in a single request
- Global Default Fallback Model: Global fallback model set in the console
- No fallback: If neither is configured, errors are returned directly on failure
Notes
- If the fallback model itself fails, the system returns an error; no secondary fallback occurs
- The response annotates the actual model used to facilitate monitoring and analysis
Best Practices
1. Prefer Global Configuration
For most scenarios, use global fallback configuration:
✅ Recommended:
- Configure a global fallback model in the console to simplify code maintenance
- Choose a highly stable, cost-effective model as the global fallback
- Regularly review fallback trigger frequency to optimize primary model configuration
❌ Avoid:
- Repeating the same fallback configuration in each request
- Selecting expensive flagship models as fallback (increases emergency costs)
2. Use Per-Request Configuration for Special Cases
Use per-request configuration only when differentiated handling is needed:
# Critical business: use a high-quality fallback model
critical_response = client.chat.completions.create(
model="anthropic/claude-4-sonnet",
extra_body={
"provider": {
"fallback": "openai/gpt-5" # High-quality fallback
}
},
messages=[...]
)
# General business: rely on globally configured economical fallback
normal_response = client.chat.completions.create(
model="anthropic/claude-4-sonnet",
messages=[...] # Use global fallback configuration
)3. Monitor Fallback Triggers
Monitor fallback trigger frequency via the model field in the response or console logs:
response = client.chat.completions.create(
model="anthropic/claude-sonnet-4",
extra_body={
"provider": {"fallback": "google/gemini-2.5-flash-lite"}
},
messages=[...]
)
# Check whether fallback was triggered
if response.model != "anthropic/claude-sonnet-4":
print(f"Warning: Fallback triggered, actual model used: {response.model}")Continuous Optimization
If fallback triggers too frequently, consider:
- Verifying the primary model’s API key configuration
- Evaluating the primary model’s quota and rate limit settings
- Adjusting the candidate model pool for intelligent routing
- Contacting technical support to troubleshoot potential issues
FAQ
Q: Does the fallback mechanism increase request latency?
A: Fallback is only triggered when the primary model fails; it does not affect performance under normal conditions. Once triggered, switching to the fallback model typically completes within seconds, with actual latency depending on the primary model timeout and fallback model response speed.
Q: Can I configure multiple fallback models?
A: Currently, only one fallback model is supported. If the fallback model itself fails, the system returns an error. We recommend selecting a highly stable model as the fallback.
Q: How can I tell if a request used the fallback model?
A: The model field in the response shows the actual model used. If it differs from the model specified in the request, the fallback mechanism was triggered. You can also review detailed request logs in the ZenMux Console.
Q: Can global fallback and per-request fallback be used together?
A: Yes. Per-request configuration has higher priority and overrides the global setting. This lets you use global configuration for most scenarios while applying differentiated fallback strategies to specific requests.
Contact Us
If you encounter any issues or have suggestions and feedback, feel free to reach us via:
- Official website: https://zenmux.ai
- Technical support email: [email protected]
- Business cooperation email: [email protected]
- Twitter: @ZenMuxAI
- Discord Community: http://discord.gg/vHZZzj84Bm
For more contact methods and details, please visit our Contact Us page.