Prompt Cache
Prompt Caching is a powerful performance optimization feature that allows you to reuse specific prefix content in your requests. This approach can significantly reduce processing time and call costs, particularly suitable for scenarios containing large amounts of static content.
💡 Core Advantages
- Cost Reduction: When cache hits occur, cached content typically costs only 10% of the original input cost
- Speed Enhancement: Reduces processing time for repeated content, accelerating response speed
- Use Cases: Long system prompts, numerous examples, RAG documents, long conversation history, etc.
Caching Types Overview
Models supported by ZenMux offer two types of prompt caching mechanisms:
| Caching Type | Usage Method | Representative Models |
|---|---|---|
| Implicit Caching | No configuration needed, automatically managed by model | OpenAI, DeepSeek, Grok, Gemini, Qwen series |
| Explicit Caching | Requires cache_control parameter | Anthropic Claude, Qwen series |
Type 1: Implicit Caching
The following model series provide implicit automatic prompt caching functionality, requiring no special parameters in requests—the model automatically detects and caches reusable content.
| Model Provider | Representative Models | Official Documentation |
|---|---|---|
| OpenAI | GPT series | Prompt Caching |
| DeepSeek | DeepSeek series | Prompt Caching |
| xAI | Grok series | Prompt Caching |
| Gemini series | Prompt Caching | |
| Alibaba | Qwen series | Prompt Caching |
| MoonshotAI | Kimi series | Prompt Caching |
| ZhipuAI | GLM series | Prompt Caching |
| InclusionAI | Ling, Ring series | - |
💰 View Specific Pricing
For each model's cache read pricing (Cache Read), visit the corresponding model detail page, for example:
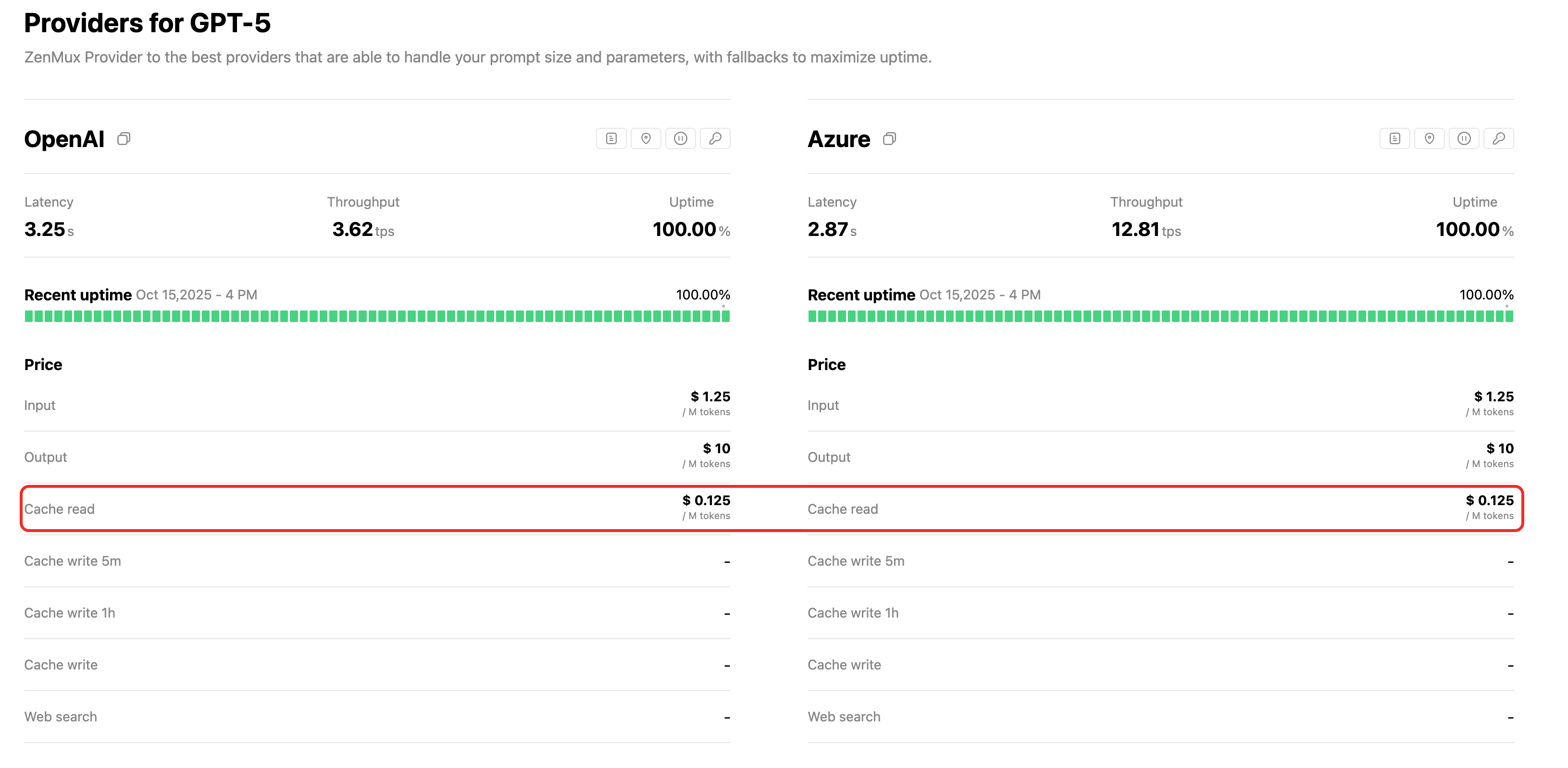
Typically, cache read fees are about 10%-25% of the original input cost, saving up to 90% of input costs.
💡 Optimization Recommendations
To maximize cache hit rate, follow these best practices:
- Static-to-Dynamic Ordering: Place stable, reusable content (such as system instructions, few-shot examples, document context) at the beginning of the messages array
- Variable Content at End: Place variable, request-specific content (such as current user question, dynamic data) at the end of the array
- Maintain Prefix Consistency: Ensure cached content remains completely consistent across multiple requests (including spaces and punctuation)
Type 2: Explicit Caching
Anthropic Claude and Qwen series models can explicitly specify caching strategies through specific parameters. This approach provides the finest control but requires you to actively manage caching strategies.
Caching Working Principle
When you send a request with cache_control markers:
- The system checks if a reusable cache prefix exists
- If a matching cache is found, cached content is used (reducing cost)
- If no match is found, the complete prompt is processed and a new cache entry is created
Cached content includes the complete prefix in the request: tools → system → messages (in this order), up to where cache_control is marked.
Automatic Prefix Check
You only need to add a cache breakpoint at the end of static content, and the system will automatically check approximately the preceding 20 content blocks for reusable cache boundaries. If the prompt contains more than 20 content blocks, consider adding additional cache_control breakpoints to ensure all content can be cached.
Caching Limitations
Minimum Cache Length
Minimum cacheable token count for different models:
| Model Series | Minimum Cache Tokens |
|---|---|
| Claude Opus 4.1/4, Sonnet 4.5/4/3.7 | 1024 tokens |
| Claude Haiku 3.5 | 2048 tokens |
| Qwen series models | 256 tokens |
Important Note
Prompts shorter than the minimum token count will not be cached even if marked with cache_control. Requests will be processed normally but no cache will be created.
Cache Validity Period
- Default TTL: 5 minutes
- Extended TTL: 1 hour (requires additional fee)
Cache automatically refreshes with each use at no additional cost.
Cache Breakpoint Count
Each request can define a maximum of 4 cache breakpoints.
Usage Methods
Basic Usage: Caching System Prompts
from openai import OpenAI
client = OpenAI(
base_url="https://zenmux.ai/api/v1",
api_key="<your_ZENMUX_API_KEY>",
)
# First request - create cache
response = client.chat.completions.create(
model="anthropic/claude-sonnet-4.5",
messages=[
{
"role": "system",
"content": [
{
"type": "text",
"text": "You are an AI assistant specializing in literary analysis. Your goal is to provide insightful commentary on themes, characters, and writing style.\n"
},
{
"type": "text",
"text": "<Complete content of Pride and Prejudice>",
"cache_control": {"type": "ephemeral"}
}
]
},
{
"role": "user",
"content": "Analyze the main themes of Pride and Prejudice."
}
]
)
print(response.choices[0].message.content)
# Second request - cache hit
response = client.chat.completions.create(
model="anthropic/claude-sonnet-4.5",
messages=[
{
"role": "system",
"content": [
{
"type": "text",
"text": "You are an AI assistant specializing in literary analysis. Your goal is to provide insightful commentary on themes, characters, and writing style.\n"
},
{
"type": "text",
"text": "<Complete content of Pride and Prejudice>",
"cache_control": {"type": "ephemeral"} # Same content hits cache #
}
]
},
{
"role": "user",
"content": "Who are the main characters in this book?" # Only question differs #
}
]
)
print(response.choices[0].message.content)import anthropic
client = anthropic.Anthropic(
base_url="https://zenmux.ai/api/anthropic",
api_key="<your_ZENMUX_API_KEY>",
)
# First request - create cache
response = client.messages.create(
model="claude-sonnet-4.5",
max_tokens=1024,
system=[
{
"type": "text",
"text": "You are an AI assistant specializing in literary analysis. Your goal is to provide insightful commentary on themes, characters, and writing style.\n"
},
{
"type": "text",
"text": "<Complete content of Pride and Prejudice>",
"cache_control": {"type": "ephemeral"}
}
],
messages=[
{
"role": "user",
"content": "Analyze the main themes of Pride and Prejudice."
}
]
)
print(response.content[0].text)
# Second request - cache hit
response = client.messages.create(
model="claude-sonnet-4.5",
max_tokens=1024,
system=[
{
"type": "text",
"text": "You are an AI assistant specializing in literary analysis. Your goal is to provide insightful commentary on themes, characters, and writing style.\n"
},
{
"type": "text",
"text": "<Complete content of Pride and Prejudice>",
"cache_control": {"type": "ephemeral"} # Same content hits cache #
}
],
messages=[
{
"role": "user",
"content": "Who are the main characters in this book?" # Only question differs #
}
]
)
print(response.content[0].text)Advanced Usage: Caching Tool Definitions
When your application uses many tools, caching tool definitions can significantly reduce costs:
from openai import OpenAI
client = OpenAI(
base_url="https://zenmux.ai/api/v1",
api_key="<your_ZENMUX_API_KEY>",
)
response = client.chat.completions.create(
model="anthropic/claude-sonnet-4.5",
tools=[
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get current weather for a specified location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "City and province, e.g. Beijing, Beijing"
},
"unit": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "Temperature unit"
}
},
"required": ["location"]
}
}
},
# Can define more tools...
{
"type": "function",
"function": {
"name": "get_time",
"description": "Get current time for a specified timezone",
"parameters": {
"type": "object",
"properties": {
"timezone": {
"type": "string",
"description": "IANA timezone name, e.g. Asia/Shanghai"
}
},
"required": ["timezone"]
}
},
"cache_control": {"type": "ephemeral"} # Mark cache on last tool #
}
],
messages=[
{
"role": "user",
"content": "What's the current weather and time in Beijing?"
}
]
)
print(response.choices[0].message)import anthropic
client = anthropic.Anthropic(
base_url="https://zenmux.ai/api/anthropic",
api_key="<your_ZENMUX_API_KEY>",
)
response = client.messages.create(
model="claude-sonnet-4.5",
max_tokens=1024,
tools=[
{
"name": "get_weather",
"description": "Get current weather for a specified location",
"input_schema": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "City and province, e.g. Beijing, Beijing"
},
"unit": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "Temperature unit"
}
},
"required": ["location"]
}
},
# Can define more tools...
{
"name": "get_time",
"description": "Get current time for a specified timezone",
"input_schema": {
"type": "object",
"properties": {
"timezone": {
"type": "string",
"description": "IANA timezone name, e.g. Asia/Shanghai"
}
},
"required": ["timezone"]
},
"cache_control": {"type": "ephemeral"} # Mark cache on last tool #
}
],
messages=[
{
"role": "user",
"content": "What's the current weather and time in Beijing?"
}
]
)
print(response.content[0].text)Tool Caching Note
By adding a cache_control marker on the last tool definition, the system will automatically cache all tool definitions as a complete prefix.
Advanced Usage: Caching Conversation History
In long conversation scenarios, you can cache the entire conversation history:
from openai import OpenAI
client = OpenAI(
base_url="https://zenmux.ai/api/v1",
api_key="<your_ZENMUX_API_KEY>",
)
response = client.chat.completions.create(
model="anthropic/claude-sonnet-4.5",
messages=[
{
"role": "system",
"content": [
{
"type": "text",
"text": "...long system prompt",
"cache_control": {"type": "ephemeral"} # Cache system prompt #
}
]
},
# Previous conversation history
{
"role": "user",
"content": "Hello, can you tell me more about the solar system?"
},
{
"role": "assistant",
"content": "Of course! The solar system is a collection of celestial bodies orbiting the sun. It consists of eight planets, numerous satellites, asteroids, comets and other celestial objects..."
},
{
"role": "user",
"content": [
{
"type": "text",
"text": "Great."
},
{
"type": "text",
"text": "Tell me more about Mars.",
"cache_control": {"type": "ephemeral"} # Cache all conversation up to here #
}
]
}
]
)
print(response.choices[0].message.content)import anthropic
client = anthropic.Anthropic(
base_url="https://zenmux.ai/api/anthropic",
api_key="<your_ZENMUX_API_KEY>",
)
response = client.messages.create(
model="claude-sonnet-4.5",
max_tokens=1024,
system=[
{
"type": "text",
"text": "...long system prompt",
"cache_control": {"type": "ephemeral"} # Cache system prompt #
}
],
messages=[
# Previous conversation history
{
"role": "user",
"content": "Hello, can you tell me more about the solar system?"
},
{
"role": "assistant",
"content": "Of course! The solar system is a collection of celestial bodies orbiting the sun. It consists of eight planets, numerous satellites, asteroids, comets and other celestial objects..."
},
{
"role": "user",
"content": [
{
"type": "text",
"text": "Great."
},
{
"type": "text",
"text": "Tell me more about Mars.",
"cache_control": {"type": "ephemeral"} # Cache all conversation up to here #
}
]
}
]
)
print(response.content[0].text)Conversation Caching Strategy
By adding cache_control to the last message of each conversation round, the system will automatically find and use the longest matching prefix from previously cached content. Even if content was previously marked with cache_control, as long as it's used within 5 minutes, it will automatically hit the cache and refresh the validity period.
Advanced Usage: Multi-Breakpoint Combination
When you have multiple content segments with different update frequencies, you can use multiple cache breakpoints:
from openai import OpenAI
client = OpenAI(
base_url="https://zenmux.ai/api/v1",
api_key="<your_ZENMUX_API_KEY>",
)
response = client.chat.completions.create(
model="anthropic/claude-sonnet-4.5",
tools=[
# Tool definitions (rarely change)
{
"type": "function",
"function": {
"name": "search_documents",
"description": "Search knowledge base",
"parameters": {
"type": "object",
"properties": {
"query": {"type": "string", "description": "Search query"}
},
"required": ["query"]
}
}
},
{
"type": "function",
"function": {
"name": "get_document",
"description": "Retrieve document by ID",
"parameters": {
"type": "object",
"properties": {
"doc_id": {"type": "string", "description": "Document ID"}
},
"required": ["doc_id"]
}
},
"cache_control": {"type": "ephemeral"} # Breakpoint 1: Tool definitions #
}
],
messages=[
{
"role": "system",
"content": [
{
"type": "text",
"text": "You are a research assistant with access to a document knowledge base.\n\n# Instructions\n- Always search for relevant documents first\n- Provide citations...",
"cache_control": {"type": "ephemeral"} # Breakpoint 2: System instructions #
},
{
"type": "text",
"text": "# Knowledge Base Context\n\nHere are the relevant documents for this conversation:\n\n## Document 1: Solar System Overview\nThe solar system consists of the sun and all celestial bodies orbiting it...\n\n## Document 2: Planetary Characteristics\nEach planet has unique characteristics...",
"cache_control": {"type": "ephemeral"} # Breakpoint 3: RAG documents #
}
]
},
{
"role": "user",
"content": "Can you search for information about Mars rovers?"
},
{
"role": "assistant",
"content": [
{
"type": "tool_use",
"id": "tool_1",
"name": "search_documents",
"input": {"query": "Mars rovers"}
}
]
},
{
"role": "user",
"content": [
{
"type": "tool_result",
"tool_use_id": "tool_1",
"content": "Found 3 relevant documents..."
}
]
},
{
"role": "assistant",
"content": "I found 3 relevant documents. Let me get more details from the Mars exploration document."
},
{
"role": "user",
"content": [
{
"type": "text",
"text": "Okay, please tell me specific information about the Perseverance rover.",
"cache_control": {"type": "ephemeral"} # Breakpoint 4: Conversation history #
}
]
}
]
)
print(response.choices[0].message.content)import anthropic
client = anthropic.Anthropic(
base_url="https://zenmux.ai/api/anthropic",
api_key="<your_ZENMUX_API_KEY>",
)
response = client.messages.create(
model="claude-sonnet-4.5",
max_tokens=1024,
tools=[
# Tool definitions (rarely change)
{
"name": "search_documents",
"description": "Search knowledge base",
"input_schema": {
"type": "object",
"properties": {
"query": {"type": "string", "description": "Search query"}
},
"required": ["query"]
}
},
{
"name": "get_document",
"description": "Retrieve document by ID",
"input_schema": {
"type": "object",
"properties": {
"doc_id": {"type": "string", "description": "Document ID"}
},
"required": ["doc_id"]
},
"cache_control": {"type": "ephemeral"} # Breakpoint 1: Tool definitions #
}
],
system=[
{
"type": "text",
"text": "You are a research assistant with access to a document knowledge base.\n\n# Instructions\n- Always search for relevant documents first\n- Provide citations...",
"cache_control": {"type": "ephemeral"} # Breakpoint 2: System instructions #
},
{
"type": "text",
"text": "# Knowledge Base Context\n\nHere are the relevant documents for this conversation:\n\n## Document 1: Solar System Overview\nThe solar system consists of the sun and all celestial bodies orbiting it...\n\n## Document 2: Planetary Characteristics\nEach planet has unique characteristics...",
"cache_control": {"type": "ephemeral"} # Breakpoint 3: RAG documents #
}
],
messages=[
{
"role": "user",
"content": "Can you search for information about Mars rovers?"
},
{
"role": "assistant",
"content": [
{
"type": "tool_use",
"id": "tool_1",
"name": "search_documents",
"input": {"query": "Mars rovers"}
}
]
},
{
"role": "user",
"content": [
{
"type": "tool_result",
"tool_use_id": "tool_1",
"content": "Found 3 relevant documents..."
}
]
},
{
"role": "assistant",
"content": "I found 3 relevant documents. Let me get more details from the Mars exploration document."
},
{
"role": "user",
"content": [
{
"type": "text",
"text": "Okay, please tell me specific information about the Perseverance rover.",
"cache_control": {"type": "ephemeral"} # Breakpoint 4: Conversation history #
}
]
}
]
)
print(response.content[0].text)Multi-Breakpoint Advantages
Using multiple cache breakpoints allows content with different update frequencies to be cached independently:
- Breakpoint 1: Tool definitions (almost never change)
- Breakpoint 2: System instructions (rarely change)
- Breakpoint 3: RAG documents (may update daily)
- Breakpoint 4: Conversation history (changes every round)
When only the conversation history is updated, the cache for the first three breakpoints remains valid, maximizing cost savings.
What Invalidates Cache
The following operations will invalidate part or all of the cache:
| Changed Content | Tool Cache | System Cache | Message Cache | Impact Description |
|---|---|---|---|---|
| Tool Definitions | ✘ | ✘ | ✘ | Modifying tool definitions invalidates entire cache |
| System Prompt | ✓ | ✘ | ✘ | Modifying system prompt invalidates system and message cache |
| tool_choice Parameter | ✓ | ✓ | ✘ | Only affects message cache |
| Add/Remove Images | ✓ | ✓ | ✘ | Only affects message cache |
Best Practices
Maximizing Cache Hit Rate
Optimization Recommendations
- Maintain Prefix Consistency: Place static content at the beginning of prompts, variable content at the end
- Use Breakpoints Wisely: Set different cache breakpoints based on content update frequency
- Avoid Minor Changes: Ensure cached content remains completely consistent across multiple requests
- Control Cache Time Window: Initiate subsequent requests within 5 minutes to hit cache
Extending Cache Time (1-hour TTL)
If your request intervals may exceed 5 minutes, consider using 1-hour cache:
{
"type": "text",
"text": "Long document content...",
"cache_control": {
"type": "ephemeral",
"ttl": "1h" # Extend to 1 hour #
}
}Note
The write cost for 1-hour cache is 2x the base fee (compared to 1.25x for 5-minute cache), only worthwhile in low-frequency but regular call scenarios.
Avoiding Common Pitfalls
Common Issues
- Cached Content Too Short: Ensure cached content meets minimum token requirements
- Content Inconsistency: Changes in JSON object key order will invalidate cache (certain languages like Go, Swift)
- Mixed Format Usage: Using different formatting approaches for the same content
- Ignoring Cache Validity Period: Cache becomes invalid after 5 minutes
FAQ
Do Implicit Caching Models Require Configuration?
No. Implicit caching models like OpenAI, DeepSeek, Grok, Gemini, Qwen automatically manage caching without requiring any special parameters in requests.
About Gemini and Qwen
These two model series support both implicit and explicit modes. Implicit mode triggers automatically, while explicit mode requires proactive control through API parameters (such as cache_control).
How to View Cache Data?
You can view the Prompt Token details of requests in the ZenMux Logs interface, as shown below:
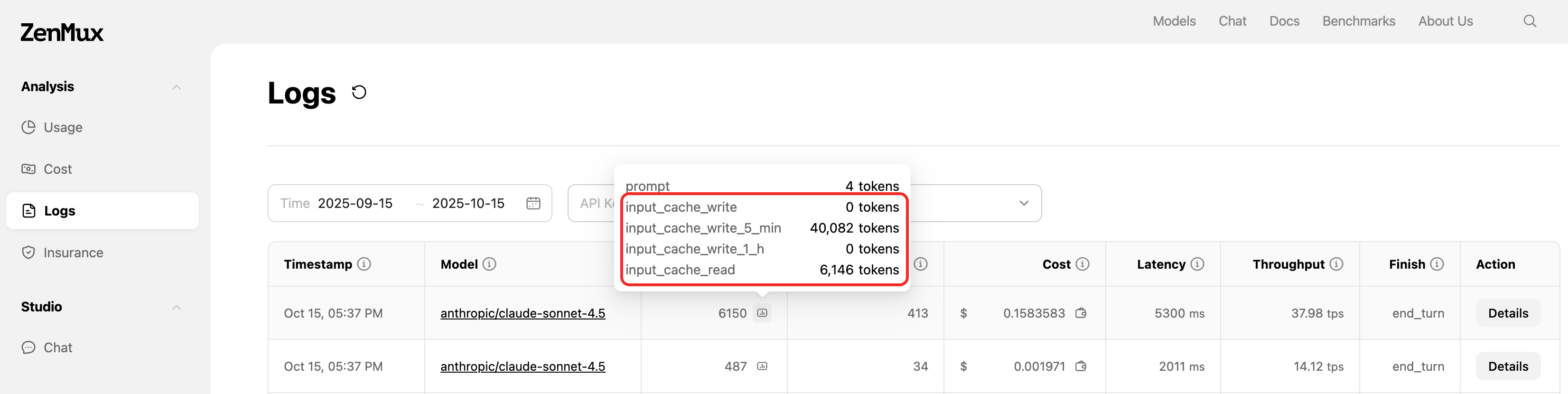
Note the Impact of Log Switch
Note that you need to enable the switch in the Strategy-API Call Logging interface for related data to be logged.
