Model Routing
Model routing is an intelligent feature of ZenMux that helps you automatically select the most suitable model from a wide range of large language models. The system intelligently balances performance and cost based on the request content, task characteristics, and your preference settings.
Intelligent model selection
No need to manually compare model performance and pricing—ZenMux automatically matches the most suitable model for each request, so you can focus on building your business logic.
Why Model Routing
In real-world applications, different tasks have different model requirements:
- Simple conversations: using a high-performance model may be wasteful
- Complex reasoning: a budget model may not meet quality requirements
- Production environments: you must balance quality, cost, and speed
- Model selection is hard: dozens of models on the market make manual selection time-consuming
Model routing solves these problems with automated decisions, intelligently matching the optimal model for each request.
Model List
Quick lookup
On the Models page you can view all supported models and their basic information. Use the filters on the left, the search box at the top, and sorting options to quickly locate the model you need. Model cards also provide quick access to supported input/output modalities, input/output pricing, Context, Max Tokens, and other key details.
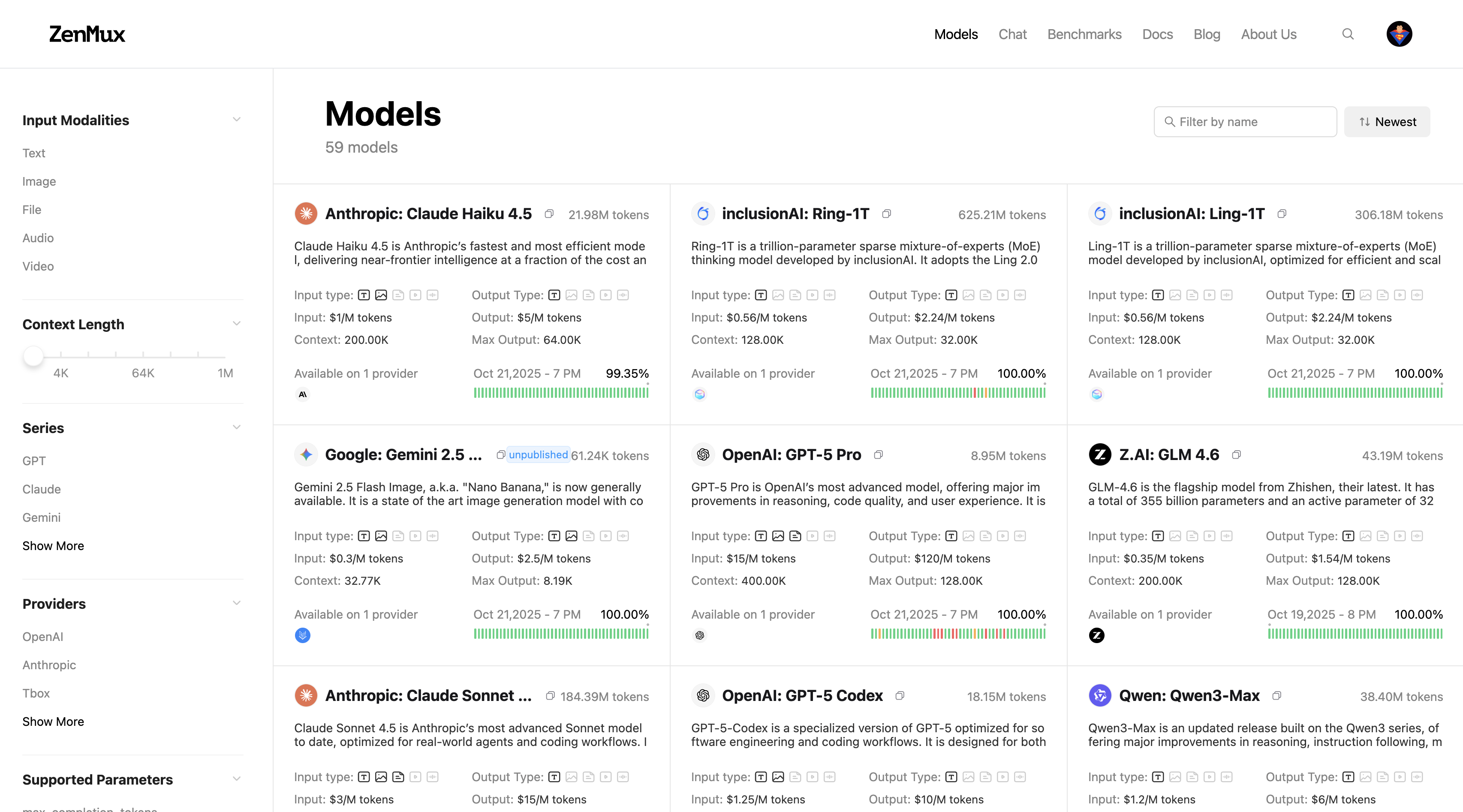
Click any model card to open its details page and view model-specific information across different providers, including performance comparisons, price comparisons, and parameter differences. For details, see the Provider Routing documentation.
Core Benefits
| Benefit | Description |
|---|---|
| Intelligent decisions | Automatically analyzes request content and task characteristics to select the most suitable model |
| Cost optimization | Prioritizes better cost-performance models while ensuring quality |
| Flexible configuration | Supports custom model pools and preference strategies for different business scenarios |
| Transparent and controllable | Returns the actual model used for easy monitoring and optimization |
| Continuous optimization | Continuously improves routing strategies based on historical data |
Quick Start
Basic Usage
Model routing is easy to use—simply set the model parameter to zenmux/auto and specify the candidate model pool via model_routing_config. If you do not specify model_routing_config.available_models, the system will use the platform’s full model pool.
How to get model slugs
Models on the ZenMux platform have unique slugs. You can get a model’s slug from the Models list page: 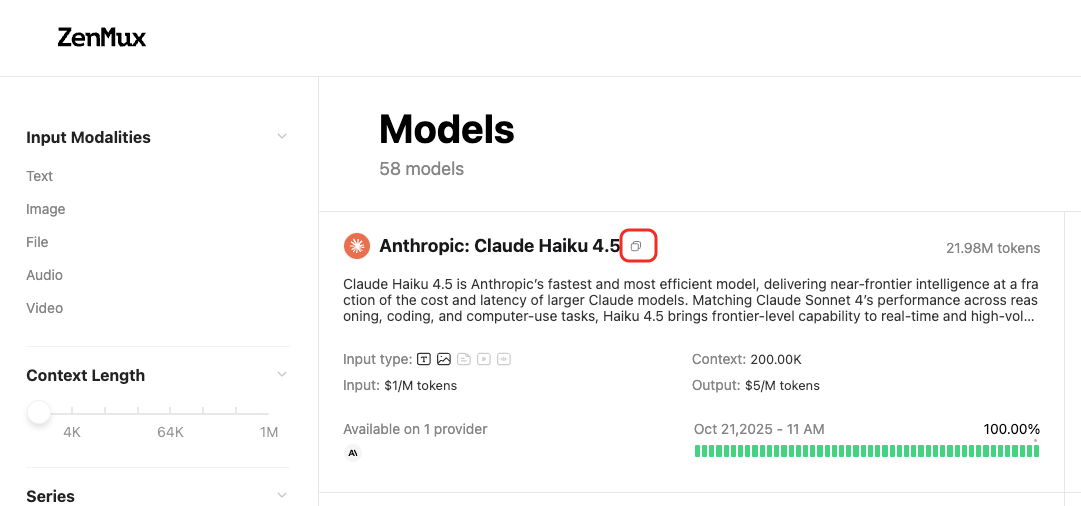 Or from the model detail page for a specific model:
Or from the model detail page for a specific model: 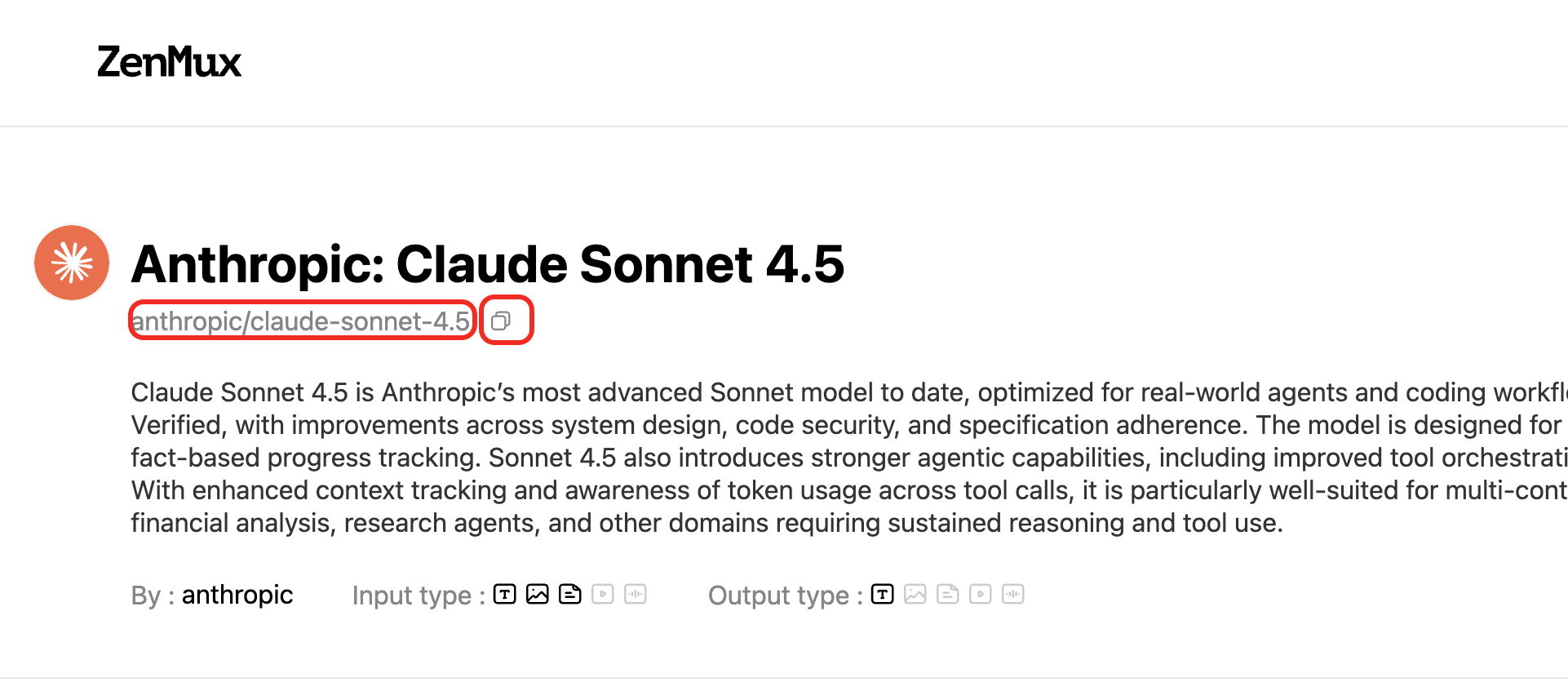
{
"model": "zenmux/auto",
"model_routing_config": {
"available_models": [
"anthropic/claude-4-sonnet", // Provide the model slug
"openai/gpt-5",
"google/gemini-2.5-flash-lite"
],
"preference": "balanced"
},
"messages": [
{
"role": "user",
"content": "Explain what quantum computing is"
}
]
}from openai import OpenAI
client = OpenAI(
base_url="https://zenmux.ai/api/v1",
api_key="<your ZENMUX_API_KEY>"
)
response = client.chat.completions.create(
model="zenmux/auto",
extra_body={
"model_routing_config": {
"available_models": [
"anthropic/claude-4-sonnet",
"openai/gpt-5",
"google/gemini-2.5-flash-lite"
],
"preference": "balanced"
}
},
messages=[
{"role": "user", "content": "Explain what quantum computing is"}
]
)
print(f"Selected model: {response.model}")
print(f"Answer: {response.choices[0].message.content}")Model actually used
The model field in the response returns the model selected by intelligent routing, making it easy to monitor and analyze routing behavior.
How It Works
zenmux/auto model
zenmux/auto is a special model identifier in ZenMux. When you specify this model, the system enables intelligent routing.
Routing decision process:
- Request analysis: parse prompt content, context length, task type, and other features
- Model evaluation: score each model in the candidate pool
- Aggregated decision: balance performance, price, and availability according to the
preferencestrategy - Model selection: choose the optimal model and forward the request
- Result return: annotate the actual model used in the response
Factors considered in routing decisions
- Task complexity: simple conversation vs. complex reasoning
- Context length: short dialogue vs. long document analysis
- Model performance: accuracy, response speed, creativity
- Model pricing: input/output token unit price
- Model availability: real-time load, regional restrictions
- User preference: performance / balanced / price
Configuration Parameters
model_routing_config object
Configure intelligent routing behavior via the model_routing_config parameter:
| Parameter | Type | Required | Description |
|---|---|---|---|
available_models | string[] | Yes | Candidate model list for routing |
preference | string | No | Routing preference strategy, default balanced |
available_models - Candidate model pool
Specify the list of models that intelligent routing can choose from. We recommend including 3–5 models across different performance and price tiers.
Notes
- The model list must include at least 2 models
- Mix models from different price tiers for optimal balance
preference - Routing preference strategy
Specify the priority strategy used in routing decisions:
balanced - Balanced mode (default)
Seeks the optimal balance between performance and cost; suitable for most application scenarios.
Characteristics:
- Prioritizes budget models for simple tasks
- Automatically upgrades to high-performance models for complex tasks
- Balances quality and cost
Suitable scenarios:
- General-purpose apps in production environments
- Mixed scenarios such as conversational assistants and content generation
- Situations where you must control cost without sacrificing quality
performance - Performance-first mode
Prioritizes the highest-performing models; suitable for scenarios with very high output quality requirements.
Characteristics:
- Tends to choose top flagship models
- Ensures the highest answer quality and accuracy
- Relatively higher cost
Suitable scenarios:
- Critical business decision support
- Professional content creation (legal, medical, finance, etc.)
- Complex code generation and debugging
- Academic research and data analysis
price - Price-first mode
Prioritizes models with the best cost-effectiveness; suitable for large-scale, cost-sensitive applications.
Characteristics:
- Prefers the cheapest models
- Only upgrades to more expensive models when necessary
- Maximizes cost efficiency
Suitable scenarios:
- High-concurrency simple conversation applications
- Internal tools and test environments
- Education and learning scenarios
- Budget-limited startup projects
Preference strategy comparison
| Strategy | Performance | Cost | Suitable scenarios |
|---|---|---|---|
balanced | ⭐⭐⭐⭐ | ⭐⭐⭐ | Production, general apps |
performance | ⭐⭐⭐⭐⭐ | ⭐⭐ | Critical business, professional content |
price | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | High concurrency, cost-sensitive |
Best Practices
1. Configure the candidate model pool appropriately
Follow these principles when choosing candidate models:
Recommended:
- Include 3–5 models across different tiers
- Mix flagship, mid-tier, and budget models
- Consider model strengths (creativity, reasoning, speed, etc.)
- Ensure all models have the necessary API keys configured
Avoid:
- Only choosing models from the same tier (loses routing advantages)
- Including too many models (increases decision complexity)
FAQ
Q: How much latency does intelligent routing add?
A: Routing decisions typically complete within 50–100 ms, with negligible impact for most applications. The actual request response time mainly depends on the selected model’s processing speed.
Q: How many models should the candidate pool include?
A: We recommend 3–5 models. Too few cannot fully leverage routing advantages; too many increase decision complexity with diminishing returns.
Q: What factors does intelligent routing consider?
A: The routing system considers multiple factors:
- Prompt content and length
- Task type (conversation, creation, reasoning, etc.)
- Model performance metrics (accuracy, speed)
- Model pricing
- Current load and availability
- Your
preferencesetting
Q: Can I view detailed routing decision logs?
A: The response returns the actual model used (response.model). You can also view call logs in the ZenMux user console to see the routing details for each request.
Q: Can I use model routing and provider routing together?
A: Yes. Model routing chooses the most suitable model, while provider routing chooses the optimal provider for the selected model. Using both together enables end-to-end intelligent optimization. For details, see the Provider Routing documentation.
Contact Us
If you encounter any issues during use or have suggestions and feedback, please contact us via:
- Official website: https://zenmux.ai
- Technical support email: [email protected]
- Business cooperation email: [email protected]
- Twitter: @ZenMuxAI
- Discord community: http://discord.gg/vHZZzj84Bm
For more contact options and details, visit our Contact Us page.