模型路由
模型路由是 ZenMux 的智能化特性,帮助您在众多大语言模型中自动选择最适合的模型。系统会根据请求内容、任务特征和您的偏好设置,智能地在性能和成本之间找到最优平衡。
智能化的模型选择
无需手动比较模型性能和价格,ZenMux 自动为每个请求匹配最合适的模型,让您专注于业务逻辑开发。
为什么需要模型路由
在实际应用中,不同的任务对模型的要求各不相同:
- 简单对话:使用高性能模型会造成成本浪费
- 复杂推理:使用经济型模型可能无法满足质量要求
- 生产环境:需要在效果、成本、速度之间权衡
- 模型选择困难:市场上有数十种模型,手动选择耗时费力
模型路由通过自动化决策解决这些问题,为每个请求智能匹配最优模型。
模型列表
快速查看
在官网的 Models 页面 可查看所有支持的模型及其基本信息。您可以通过左侧的筛选条件、顶部的搜索框、排序选项等快速定位所需模型。也可以通过模型卡片快速获取到模型的输入、输出支持模态;input/output 价格;Context 和 Max Tokens 等关键信息。
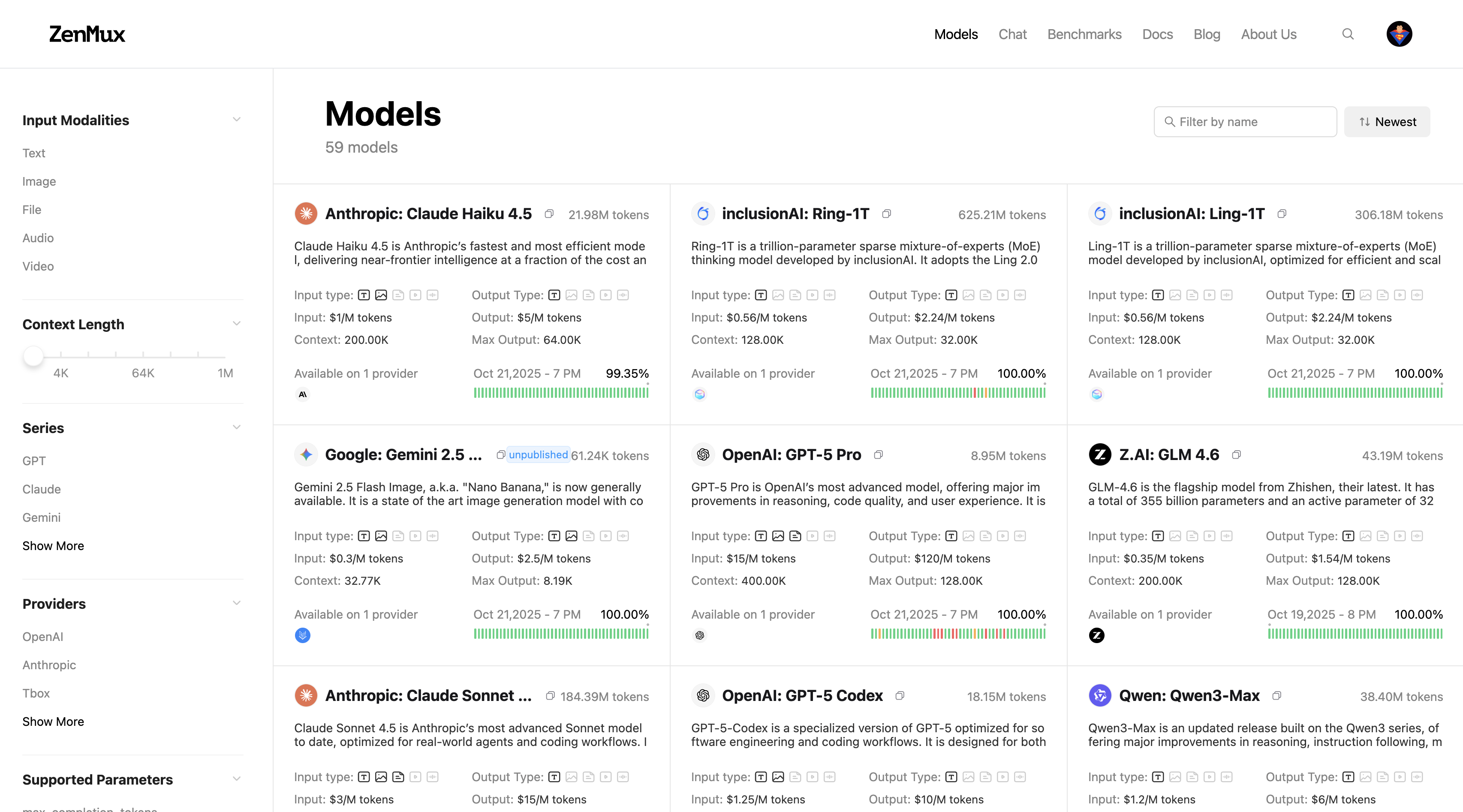
点击任意模型卡片可进入该模型的详情页,查看该模型在不同供应商的详细信息,包括性能对比、价格对比、参数对比等。详情请参考供应商路由文档。
核心优势
| 优势特性 | 说明 |
|---|---|
| 智能决策 | 自动分析请求内容和任务特征,选择最适合的模型 |
| 成本优化 | 在保证效果的前提下,优先选择性价比更高的模型 |
| 灵活配置 | 支持自定义模型池和偏好策略,适应不同业务场景 |
| 透明可控 | 返回实际使用的模型信息,方便监控和优化 |
| 持续优化 | 基于历史数据不断优化路由策略,提升决策质量 |
快速开始
基础用法
使用模型路由非常简单,只需将 model 参数设置为 zenmux/auto,并通过 model_routing_config 指定候选模型池即可。如果您未指定 model_routing_config.available_models,系统将使用平台全量的模型池。
模型 Slug 获取说明
ZenMux 平台的模型具备唯一 Slug,您可以通过模型列表页获取对应模型的 Slug: 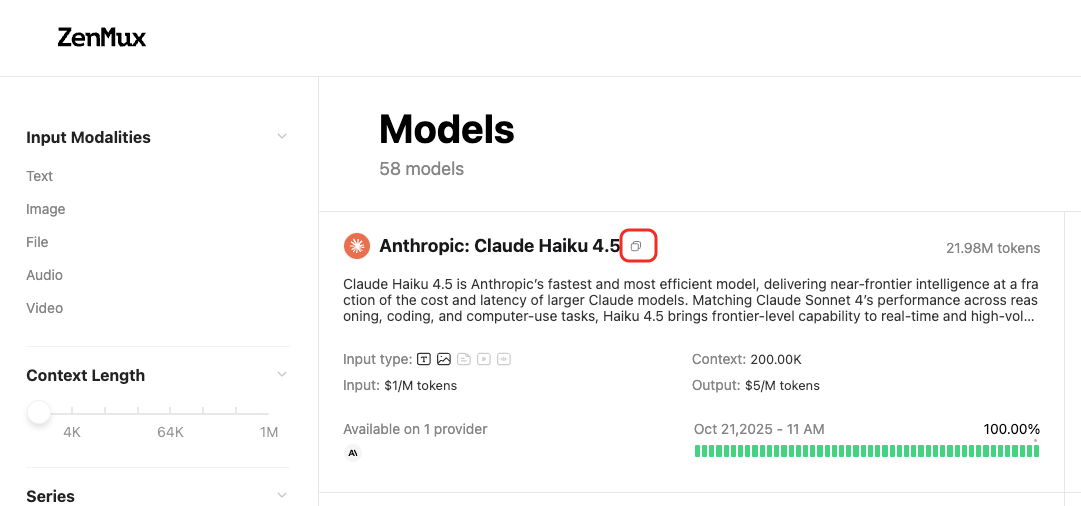 或者某个模型的模型详情页获取对应模型的 Slug:
或者某个模型的模型详情页获取对应模型的 Slug: 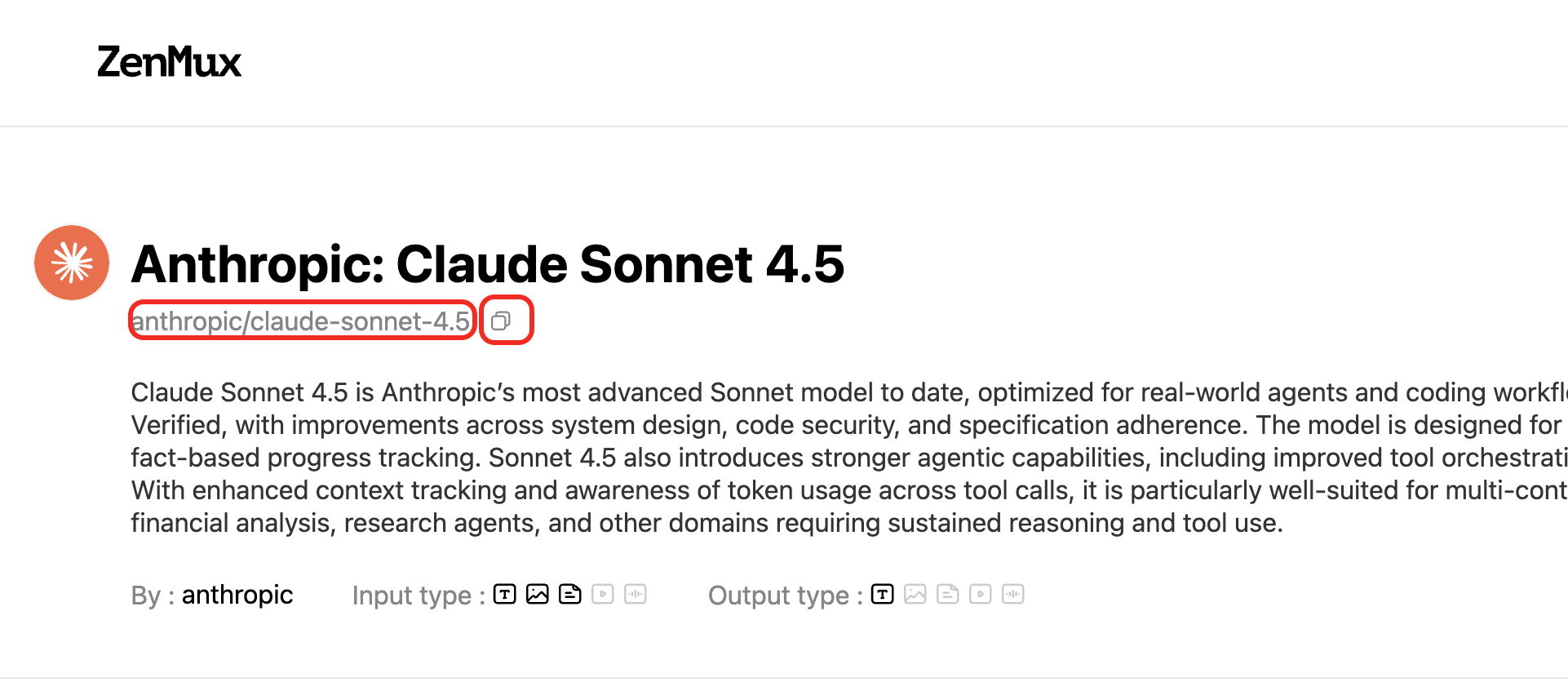
{
"model": "zenmux/auto",
"model_routing_config": {
"available_models": [
"anthropic/claude-4-sonnet", // 填写模型 Slug
"openai/gpt-5",
"google/gemini-2.5-flash-lite"
],
"preference": "balanced"
},
"messages": [
{
"role": "user",
"content": "解释一下什么是量子计算"
}
]
}from openai import OpenAI
client = OpenAI(
base_url="https://zenmux.ai/api/v1",
api_key="<你的 ZENMUX_API_KEY>"
)
response = client.chat.completions.create(
model="zenmux/auto",
extra_body={
"model_routing_config": {
"available_models": [
"anthropic/claude-4-sonnet",
"openai/gpt-5",
"google/gemini-2.5-flash-lite"
],
"preference": "balanced"
}
},
messages=[
{"role": "user", "content": "解释一下什么是量子计算"}
]
)
print(f"选中的模型: {response.model}")
print(f"回答: {response.choices[0].message.content}")实际使用的模型
响应中的 model 字段会返回智能路由实际选择的模型,便于您监控和分析路由行为。
工作原理
zenmux/auto 模型
zenmux/auto 是 ZenMux 的特殊模型标识符,当您指定此模型时,系统会启用智能路由功能。
路由决策流程:
- 请求分析:解析提示词内容、上下文长度、任务类型等特征
- 模型评估:对候选模型池中的每个模型进行评分
- 综合决策:根据
preference策略在性能、价格、可用性之间平衡 - 模型选择:选出最优模型并转发请求
- 结果返回:在响应中标注实际使用的模型
路由决策考虑的因素
- 任务复杂度:简单对话 vs 复杂推理
- 上下文长度:短对话 vs 长文档分析
- 模型性能:准确率、响应速度、创造力
- 模型价格:输入/输出 token 单价
- 模型可用性:实时负载、区域限制
- 用户偏好:performance / balanced / price
配置参数详解
model_routing_config 对象
通过 model_routing_config 参数配置智能路由的行为:
| 参数 | 类型 | 必填 | 说明 |
|---|---|---|---|
available_models | string[] | 是 | 候选模型列表,路由将从中选择 |
preference | string | 否 | 路由偏好策略,默认 balanced |
available_models - 候选模型池
指定智能路由可以选择的模型列表。建议包含 3-5 个不同性能和价格档次的模型。
注意事项
- 模型列表中至少需要包含 2 个模型
- 建议混合不同价格档次的模型以获得最佳平衡效果
preference - 路由偏好策略
指定智能路由在决策时的优先级策略:
balanced - 均衡模式(默认)
在性能和成本之间寻求最佳平衡,适合大多数应用场景。
特点:
- 简单任务优先选择经济型模型
- 复杂任务自动升级到高性能模型
- 兼顾效果和成本
适用场景:
- 生产环境中的通用应用
- 对话助手、内容生成等混合场景
- 需要控制成本但不能牺牲质量的场景
performance - 性能优先模式
优先选择性能最强的模型,适合对输出质量要求极高的场景。
特点:
- 倾向于选择最强的旗舰级模型
- 确保最高的回答质量和准确性
- 成本相对较高
适用场景:
- 关键业务决策支持
- 专业内容创作(法律、医疗、金融等)
- 复杂的代码生成和调试
- 学术研究和数据分析
price - 价格优先模式
优先选择性价比最高的模型,适合成本敏感的大规模应用。
特点:
- 优先选择最便宜的模型
- 只在必要时才升级到更贵的模型
- 最大化成本效益
适用场景:
- 高并发的简单对话应用
- 内部工具和测试环境
- 教育和学习场景
- 预算有限的初创项目
偏好策略对比
| 策略 | 性能 | 成本 | 适用场景 |
|---|---|---|---|
balanced | ⭐⭐⭐⭐ | ⭐⭐⭐ | 生产环境、通用应用 |
performance | ⭐⭐⭐⭐⭐ | ⭐⭐ | 关键业务、专业内容 |
price | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 高并发、成本敏感 |
最佳实践
1. 合理配置候选模型池
选择候选模型时应遵循以下原则:
✅ 推荐做法:
- 包含 3-5 个不同档次的模型
- 混合旗舰级、中端、经济型模型
- 考虑不同模型的特长(创意、推理、速度等)
- 确保所有模型都已配置好必要的 API 密钥
❌ 避免:
- 只选择同一档次的模型(失去路由优势)
- 包含过多模型(增加决策复杂度)
常见问题
Q: 智能路由会增加多少延迟?
A: 路由决策通常在 50-100ms 内完成,对于大多数应用场景影响可忽略。实际的请求响应时间主要取决于所选模型的处理速度。
Q: 候选模型池应该包含多少个模型?
A: 建议 3-5 个模型。太少无法充分利用路由优势,太多会增加决策复杂度且收益递减。
Q: 智能路由的决策依据是什么?
A: 路由系统会综合考虑多个因素:
- 请求的提示词内容和长度
- 任务类型(对话、创作、推理等)
- 模型的性能指标(准确率、速度)
- 模型的价格
- 当前的负载和可用性
- 您设置的
preference偏好
Q: 可以看到详细的路由决策日志吗?
A: 当前响应中会返回实际使用的模型(response.model)。或者通过 ZenMux 用户控制台查看调用日志,了解每次请求的路由详情。
Q: 可以同时使用模型路由和供应商路由吗?
A: 可以。模型路由用于选择最合适的模型,供应商路由用于为选定的模型选择最优供应商。两者结合使用可以实现端到端的智能优化。具体请参考供应商路由文档。
联系我们
如果您在使用过程中遇到任何问题,或有任何建议和反馈,欢迎通过以下方式联系我们:
- 官方网站:https://zenmux.ai
- 技术支持邮箱:[email protected]
- 商务合作邮箱:[email protected]
- Twitter:@ZenMuxAI
- Discord 社区:http://discord.gg/vHZZzj84Bm
更多联系方式和详细信息,请访问我们的联系我们页面。