提示词缓存
提示词缓存(Prompt Caching)是一种强大的性能优化功能,可以让你重复使用请求中的特定前缀内容。这种方式能够显著减少处理时间和调用成本,特别适用于包含大量静态内容的场景。
💡 核心优势
- 降低成本: 缓存命中时,缓存内容的费用通常只有原始输入成本的 10%
- 提升速度: 减少重复内容的处理时间,加快响应速度
- 适用场景: 长系统提示词、大量示例、RAG 文档、长对话历史等
缓存类型概览
ZenMux 支持的模型提供两种类型的提示词缓存机制:
| 缓存类型 | 使用方式 | 代表模型 |
|---|---|---|
| 隐式缓存 | 无需配置,模型自动管理 | OpenAI、DeepSeek、Grok、Gemini、Qwen 系列 |
| 显式缓存 | 需要使用 cache_control 参数 | Anthropic Claude、Qwen 系列 |
类型一: 隐式缓存
以下模型系列提供隐式自动提示词缓存功能,无需在请求中添加任何特殊参数,模型会自动检测和缓存可复用的内容。
| 模型厂商 | 代表模型 | 官方文档说明 |
|---|---|---|
| OpenAI | GPT 系列 | Prompt Caching |
| DeepSeek | DeepSeek 系列 | Prompt Caching |
| xAI | Grok 系列 | Prompt Caching |
| Gemini 系列 | Prompt Caching | |
| Alibaba | Qwen 系列 | Prompt Caching |
| MoonshotAI | Kimi 系列 | Prompt Caching |
| ZhipuAI | GLM 系列 | Prompt Caching |
| InclusionAI | Ling, Ring 系列 | - |
💰 查看具体价格
每个模型的缓存读取价格(Cache Read)请访问对应的模型详情页查看,例如:
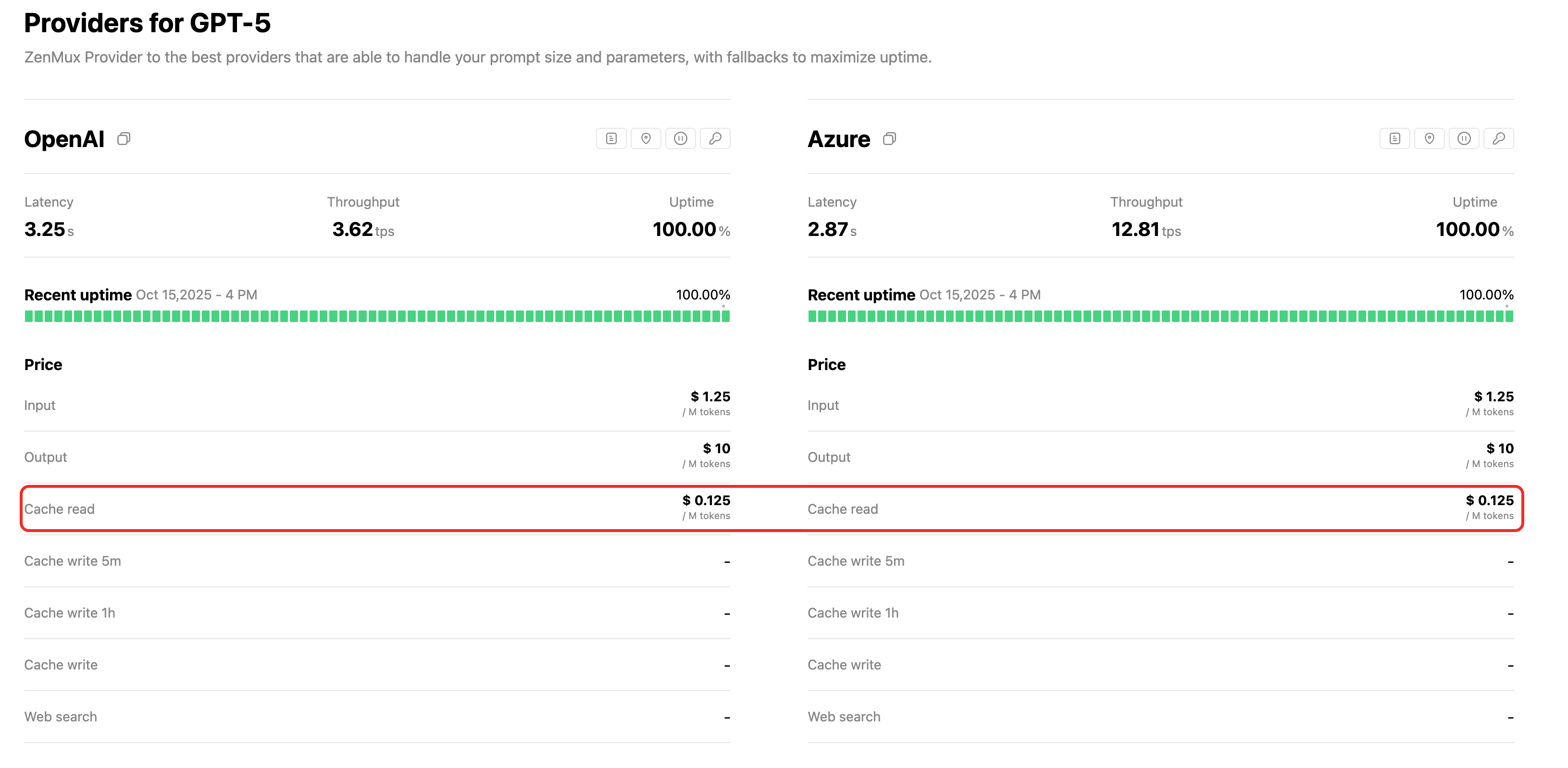
通常缓存读取费用约为原始输入成本的 10%-25%,可节省高达 90% 的输入成本。
💡 优化建议
为了最大化缓存命中率,建议遵循以下最佳实践:
- 静态到动态排序: 将稳定、可复用的内容(如系统指令、少样本示例、文档上下文)放置在 messages 数组的开头
- 变化内容置后: 将可变的、针对单次请求的内容(如用户当前问题、动态数据)放置在数组末尾
- 保持前缀一致: 确保缓存内容在多次请求间保持完全一致(包括空格、标点符号)
类型二: 显式缓存
Anthropic Claude 和 Qwen 系列模型可以通过特定参数显式指定缓存策略。这种方式提供了最精细的控制,但需要你主动管理缓存策略。
缓存工作原理
当你发送带有 cache_control 标记的请求时:
- 系统检查是否存在可复用的缓存前缀
- 如果找到匹配的缓存,则使用缓存内容(降低成本)
- 如果没有找到,则处理完整提示词并创建新的缓存条目
缓存的内容包括请求中的完整前缀:tools → system → messages(按此顺序),直到标记了 cache_control 的位置。
自动前缀检查
你只需要在静态内容的末尾添加一个缓存断点,系统会自动检查前面约 20 个内容块的边界位置是否有可复用的缓存。如果提示词包含超过 20 个内容块,建议添加额外的 cache_control 断点以确保所有内容都能被缓存。
缓存限制
最小缓存长度
不同模型的最小可缓存 token 数量:
| 模型系列 | 最小缓存 Token 数 |
|---|---|
| Claude Opus 4.1/4, Sonnet 4.5/4/3.7 | 1024 tokens |
| Claude Haiku 3.5 | 2048 tokens |
| Qwen 系列模型 | 256 tokens |
重要提示
短于最小 token 数的提示词即使标记了 cache_control 也不会被缓存,请求会正常处理但不创建缓存。
缓存有效期
- 默认 TTL: 5 分钟
- 扩展 TTL: 1 小时(需要额外费用)
缓存会在每次使用时自动刷新,无需额外费用。
缓存断点数量
每个请求最多可以定义 4 个缓存断点。
使用方法
基础用法: 缓存系统提示词
from openai import OpenAI
client = OpenAI(
base_url="https://zenmux.ai/api/v1",
api_key="<你的 ZENMUX_API_KEY>",
)
# 第一次请求 - 创建缓存
response = client.chat.completions.create(
model="anthropic/claude-sonnet-4.5",
messages=[
{
"role": "system",
"content": [
{
"type": "text",
"text": "你是一位AI助手,专门负责分析文学作品。你的目标是提供关于主题、人物和写作风格的深刻评论。\n"
},
{
"type": "text",
"text": "<《傲慢与偏见》的完整内容>",
"cache_control": {"type": "ephemeral"}
}
]
},
{
"role": "user",
"content": "分析《傲慢与偏见》的主要主题。"
}
]
)
print(response.choices[0].message.content)
# 第二次请求 - 命中缓存
response = client.chat.completions.create(
model="anthropic/claude-sonnet-4.5",
messages=[
{
"role": "system",
"content": [
{
"type": "text",
"text": "你是一位AI助手,专门负责分析文学作品。你的目标是提供关于主题、人物和写作风格的深刻评论。\n"
},
{
"type": "text",
"text": "<《傲慢与偏见》的完整内容>",
"cache_control": {"type": "ephemeral"} # 相同内容会命中缓存 #
}
]
},
{
"role": "user",
"content": "这本书的主要人物有哪些?" # 只有问题不同 #
}
]
)
print(response.choices[0].message.content)import anthropic
client = anthropic.Anthropic(
base_url="https://zenmux.ai/api/anthropic",
api_key="<你的 ZENMUX_API_KEY>",
)
# 第一次请求 - 创建缓存
response = client.messages.create(
model="claude-sonnet-4.5",
max_tokens=1024,
system=[
{
"type": "text",
"text": "你是一位AI助手,专门负责分析文学作品。你的目标是提供关于主题、人物和写作风格的深刻评论。\n"
},
{
"type": "text",
"text": "<《傲慢与偏见》的完整内容>",
"cache_control": {"type": "ephemeral"}
}
],
messages=[
{
"role": "user",
"content": "分析《傲慢与偏见》的主要主题。"
}
]
)
print(response.content[0].text)
# 第二次请求 - 命中缓存
response = client.messages.create(
model="claude-sonnet-4.5",
max_tokens=1024,
system=[
{
"type": "text",
"text": "你是一位AI助手,专门负责分析文学作品。你的目标是提供关于主题、人物和写作风格的深刻评论。\n"
},
{
"type": "text",
"text": "<《傲慢与偏见》的完整内容>",
"cache_control": {"type": "ephemeral"} # 相同内容会命中缓存 #
}
],
messages=[
{
"role": "user",
"content": "这本书的主要人物有哪些?" # 只有问题不同 #
}
]
)
print(response.content[0].text)高级用法: 缓存工具定义
当你的应用使用大量工具时,缓存工具定义可以显著降低成本:
from openai import OpenAI
client = OpenAI(
base_url="https://zenmux.ai/api/v1",
api_key="<你的 ZENMUX_API_KEY>",
)
response = client.chat.completions.create(
model="anthropic/claude-sonnet-4.5",
tools=[
{
"type": "function",
"function": {
"name": "get_weather",
"description": "获取指定地点的当前天气",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "城市和省份,例如 北京, 北京"
},
"unit": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "温度单位"
}
},
"required": ["location"]
}
}
},
# 可以定义更多工具...
{
"type": "function",
"function": {
"name": "get_time",
"description": "获取指定时区的当前时间",
"parameters": {
"type": "object",
"properties": {
"timezone": {
"type": "string",
"description": "IANA 时区名称,例如 Asia/Shanghai"
}
},
"required": ["timezone"]
}
},
"cache_control": {"type": "ephemeral"} # 在最后一个工具上标记缓存 #
}
],
messages=[
{
"role": "user",
"content": "北京现在的天气和时间是什么?"
}
]
)
print(response.choices[0].message)import anthropic
client = anthropic.Anthropic(
base_url="https://zenmux.ai/api/anthropic",
api_key="<你的 ZENMUX_API_KEY>",
)
response = client.messages.create(
model="claude-sonnet-4.5",
max_tokens=1024,
tools=[
{
"name": "get_weather",
"description": "获取指定地点的当前天气",
"input_schema": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "城市和省份,例如 北京, 北京"
},
"unit": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "温度单位"
}
},
"required": ["location"]
}
},
# 可以定义更多工具...
{
"name": "get_time",
"description": "获取指定时区的当前时间",
"input_schema": {
"type": "object",
"properties": {
"timezone": {
"type": "string",
"description": "IANA 时区名称,例如 Asia/Shanghai"
}
},
"required": ["timezone"]
},
"cache_control": {"type": "ephemeral"} # 在最后一个工具上标记缓存 #
}
],
messages=[
{
"role": "user",
"content": "北京现在的天气和时间是什么?"
}
]
)
print(response.content[0].text)工具缓存说明
在最后一个工具定义上添加 cache_control 标记,系统会自动缓存所有工具定义作为一个完整的前缀。
高级用法: 缓存对话历史
在长对话场景中,你可以缓存整个对话历史:
from openai import OpenAI
client = OpenAI(
base_url="https://zenmux.ai/api/v1",
api_key="<你的 ZENMUX_API_KEY>",
)
response = client.chat.completions.create(
model="anthropic/claude-sonnet-4.5",
messages=[
{
"role": "system",
"content": [
{
"type": "text",
"text": "...长系统提示词",
"cache_control": {"type": "ephemeral"} # 缓存系统提示词 #
}
]
},
# 之前的对话历史
{
"role": "user",
"content": "你好,请告诉我更多关于太阳系的信息?"
},
{
"role": "assistant",
"content": "当然!太阳系是围绕太阳运行的天体集合。它由八大行星、众多卫星、小行星、彗星和其他天体组成..."
},
{
"role": "user",
"content": [
{
"type": "text",
"text": "很好。"
},
{
"type": "text",
"text": "告诉我更多关于火星的信息。",
"cache_control": {"type": "ephemeral"} # 缓存到此为止的所有对话 #
}
]
}
]
)
print(response.choices[0].message.content)import anthropic
client = anthropic.Anthropic(
base_url="https://zenmux.ai/api/anthropic",
api_key="<你的 ZENMUX_API_KEY>",
)
response = client.messages.create(
model="claude-sonnet-4.5",
max_tokens=1024,
system=[
{
"type": "text",
"text": "...长系统提示词",
"cache_control": {"type": "ephemeral"} # 缓存系统提示词 #
}
],
messages=[
# 之前的对话历史
{
"role": "user",
"content": "你好,请告诉我更多关于太阳系的信息?"
},
{
"role": "assistant",
"content": "当然!太阳系是围绕太阳运行的天体集合。它由八大行星、众多卫星、小行星、彗星和其他天体组成..."
},
{
"role": "user",
"content": [
{
"type": "text",
"text": "很好。"
},
{
"type": "text",
"text": "告诉我更多关于火星的信息。",
"cache_control": {"type": "ephemeral"} # 缓存到此为止的所有对话 #
}
]
}
]
)
print(response.content[0].text)对话缓存策略
在每轮对话的最后一条消息上添加 cache_control,系统会自动查找并使用之前缓存的最长匹配前缀。即使之前标记过 cache_control 的内容,只要在 5 分钟内使用,就会自动命中缓存并刷新有效期。
高级用法: 多断点组合
当你有多个更新频率不同的内容段时,可以使用多个缓存断点:
from openai import OpenAI
client = OpenAI(
base_url="https://zenmux.ai/api/v1",
api_key="<你的 ZENMUX_API_KEY>",
)
response = client.chat.completions.create(
model="anthropic/claude-sonnet-4.5",
tools=[
# 工具定义(很少变化)
{
"type": "function",
"function": {
"name": "search_documents",
"description": "搜索知识库",
"parameters": {
"type": "object",
"properties": {
"query": {"type": "string", "description": "搜索查询"}
},
"required": ["query"]
}
}
},
{
"type": "function",
"function": {
"name": "get_document",
"description": "根据ID检索文档",
"parameters": {
"type": "object",
"properties": {
"doc_id": {"type": "string", "description": "文档ID"}
},
"required": ["doc_id"]
}
},
"cache_control": {"type": "ephemeral"} # 断点1: 工具定义 #
}
],
messages=[
{
"role": "system",
"content": [
{
"type": "text",
"text": "你是一个研究助手,可以访问文档知识库。\n\n# 指令\n- 总是先搜索相关文档\n- 提供引用来源...",
"cache_control": {"type": "ephemeral"} # 断点2: 系统指令 #
},
{
"type": "text",
"text": "# 知识库上下文\n\n以下是本次对话的相关文档:\n\n## 文档1: 太阳系概览\n太阳系由太阳和所有围绕它运行的天体组成...\n\n## 文档2: 行星特征\n每个行星都有独特的特征...",
"cache_control": {"type": "ephemeral"} # 断点3: RAG 文档 #
}
]
},
{
"role": "user",
"content": "你能搜索一下关于火星探测器的信息吗?"
},
{
"role": "assistant",
"content": [
{
"type": "tool_use",
"id": "tool_1",
"name": "search_documents",
"input": {"query": "火星探测器"}
}
]
},
{
"role": "user",
"content": [
{
"type": "tool_result",
"tool_use_id": "tool_1",
"content": "找到3个相关文档..."
}
]
},
{
"role": "assistant",
"content": "我找到了3个相关文档。让我从火星探测文档中获取更多细节。"
},
{
"role": "user",
"content": [
{
"type": "text",
"text": "好的,请告诉我关于毅力号探测器的具体信息。",
"cache_control": {"type": "ephemeral"} # 断点4: 对话历史 #
}
]
}
]
)
print(response.choices[0].message.content)import anthropic
client = anthropic.Anthropic(
base_url="https://zenmux.ai/api/anthropic",
api_key="<你的 ZENMUX_API_KEY>",
)
response = client.messages.create(
model="claude-sonnet-4.5",
max_tokens=1024,
tools=[
# 工具定义(很少变化)
{
"name": "search_documents",
"description": "搜索知识库",
"input_schema": {
"type": "object",
"properties": {
"query": {"type": "string", "description": "搜索查询"}
},
"required": ["query"]
}
},
{
"name": "get_document",
"description": "根据ID检索文档",
"input_schema": {
"type": "object",
"properties": {
"doc_id": {"type": "string", "description": "文档ID"}
},
"required": ["doc_id"]
},
"cache_control": {"type": "ephemeral"} # 断点1: 工具定义 #
}
],
system=[
{
"type": "text",
"text": "你是一个研究助手,可以访问文档知识库。\n\n# 指令\n- 总是先搜索相关文档\n- 提供引用来源...",
"cache_control": {"type": "ephemeral"} # 断点2: 系统指令 #
},
{
"type": "text",
"text": "# 知识库上下文\n\n以下是本次对话的相关文档:\n\n## 文档1: 太阳系概览\n太阳系由太阳和所有围绕它运行的天体组成...\n\n## 文档2: 行星特征\n每个行星都有独特的特征...",
"cache_control": {"type": "ephemeral"} # 断点3: RAG 文档 #
}
],
messages=[
{
"role": "user",
"content": "你能搜索一下关于火星探测器的信息吗?"
},
{
"role": "assistant",
"content": [
{
"type": "tool_use",
"id": "tool_1",
"name": "search_documents",
"input": {"query": "火星探测器"}
}
]
},
{
"role": "user",
"content": [
{
"type": "tool_result",
"tool_use_id": "tool_1",
"content": "找到3个相关文档..."
}
]
},
{
"role": "assistant",
"content": "我找到了3个相关文档。让我从火星探测文档中获取更多细节。"
},
{
"role": "user",
"content": [
{
"type": "text",
"text": "好的,请告诉我关于毅力号探测器的具体信息。",
"cache_control": {"type": "ephemeral"} # 断点4: 对话历史 #
}
]
}
]
)
print(response.content[0].text)多断点优势
使用多个缓存断点可以让不同更新频率的内容独立缓存:
- 断点 1: 工具定义(几乎不变)
- 断点 2: 系统指令(很少变化)
- 断点 3: RAG 文档(可能每天更新)
- 断点 4: 对话历史(每轮都变化)
当只更新对话历史时,前三个断点的缓存仍然有效,最大化成本节省。
什么会使缓存失效
以下操作会导致部分或全部缓存失效:
| 变更内容 | 工具缓存 | 系统缓存 | 消息缓存 | 影响说明 |
|---|---|---|---|---|
| 工具定义 | ✘ | ✘ | ✘ | 修改工具定义使整个缓存失效 |
| 系统提示词 | ✓ | ✘ | ✘ | 修改系统提示词使系统和消息缓存失效 |
| tool_choice 参数 | ✓ | ✓ | ✘ | 仅影响消息缓存 |
| 添加/删除图片 | ✓ | ✓ | ✘ | 仅影响消息缓存 |
最佳实践
最大化缓存命中率
优化建议
- 保持前缀一致: 将静态内容放在提示词开头,变化的内容放在末尾
- 合理使用断点: 根据内容更新频率设置不同的缓存断点
- 避免微小变动: 确保缓存内容在多次请求间保持完全一致
- 控制缓存时间窗口: 在 5 分钟内发起后续请求以命中缓存
扩展缓存时间(1 小时 TTL)
如果你的请求间隔可能超过 5 分钟,可以考虑使用 1 小时缓存:
{
"type": "text",
"text": "长文档内容...",
"cache_control": {
"type": "ephemeral",
"ttl": "1h" # 扩展到1小时 #
}
}注意
1 小时缓存的写入成本是基础费用的 2x(相比 5 分钟缓存的 1.25x),只在低频率但规律的调用场景中划算。
避免常见陷阱
常见问题
- 缓存内容过短: 确保缓存内容达到最小 token 要求
- 内容不一致: JSON 对象的 key 顺序变化会导致缓存失效(某些语言如 Go、Swift)
- 混用不同格式: 同一内容使用不同的格式化方式
- 忽略缓存有效期: 超过 5 分钟后缓存已失效
常见问题
隐式缓存模型是否需要配置?
不需要。OpenAI、DeepSeek、Grok、Gemini、Qwen 等隐式缓存模型会自动管理缓存,无需在请求中添加任何特殊参数。
关于 Gemini 和 Qwen
这两个模型系列同时支持隐式和显式两种模式。隐式模式自动触发,显式模式需要通过 API 参数(如 cache_control)来主动控制。
如何查看缓存数据?
你可以通过在 ZenMux Logs 界面查看请求的 Prompt Token 明细,如下图所示
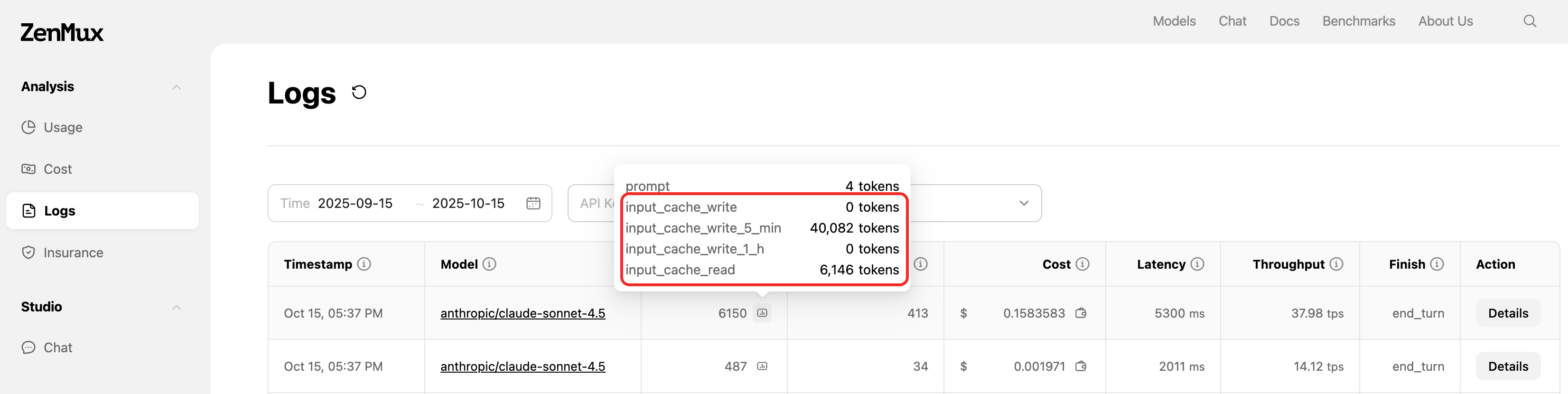
注意 log 开关的影响
注意您需要在 Strategy-API Call Logging 界面打开开关才会进行相关数据的 log。
