用量分析(Usage Analytics)
ZenMux 提供了全面的使用量分析功能,帮助您实时监控和分析 API 调用的使用情况、服务提供商表现以及模型性能。通过使用分析功能,您可以深入了解 Token 消耗、API 请求量、响应速度等关键指标,从而优化应用效率并控制成本。
提示:当前页面显示的数据不包含订阅计划中的使用数据,仅统计即用即付(Pay As You Go)的部分。
用量概览(Usage)
在“Usage”标签页中,您可以查看整体的资源消耗情况,包括 Token 使用量和 API 请求次数。
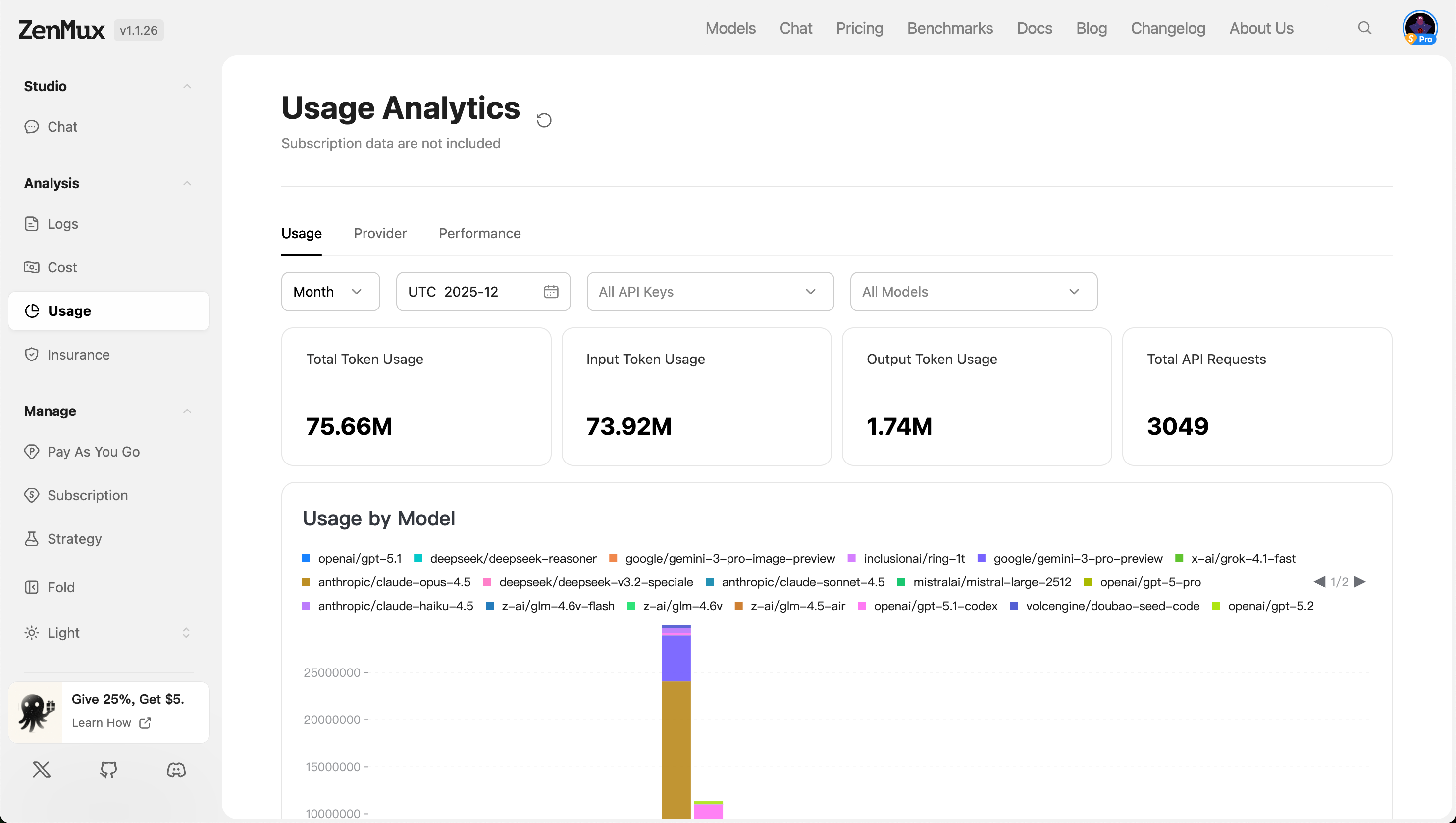
筛选条件:
- 时间范围:支持按“Month”、“Week”、“Day”等粒度筛选。
- API Keys:可选择特定 API 密钥进行数据过滤,支持“所有密钥”或单个密钥。
- 模型范围:可选择“所有模型”或指定某类模型进行分析。
指标说明
| 指标 | 说明 |
|---|---|
| Total Token Usage | 所有模型的总 Token 使用量(输入 + 输出)。 |
| Input Token Usage | 所有请求中输入部分的 Token 总数。 |
| Output Token Usage | 所有响应中输出部分的 Token 总数。 |
| Total API Requests | 在指定时间段内的 API 调用总次数。 |
各维度分析
- 按模型分布(Usage by Model)
展示各模型的 Token 使用分布情况,以图表或表格形式呈现,帮助识别高消耗模型。
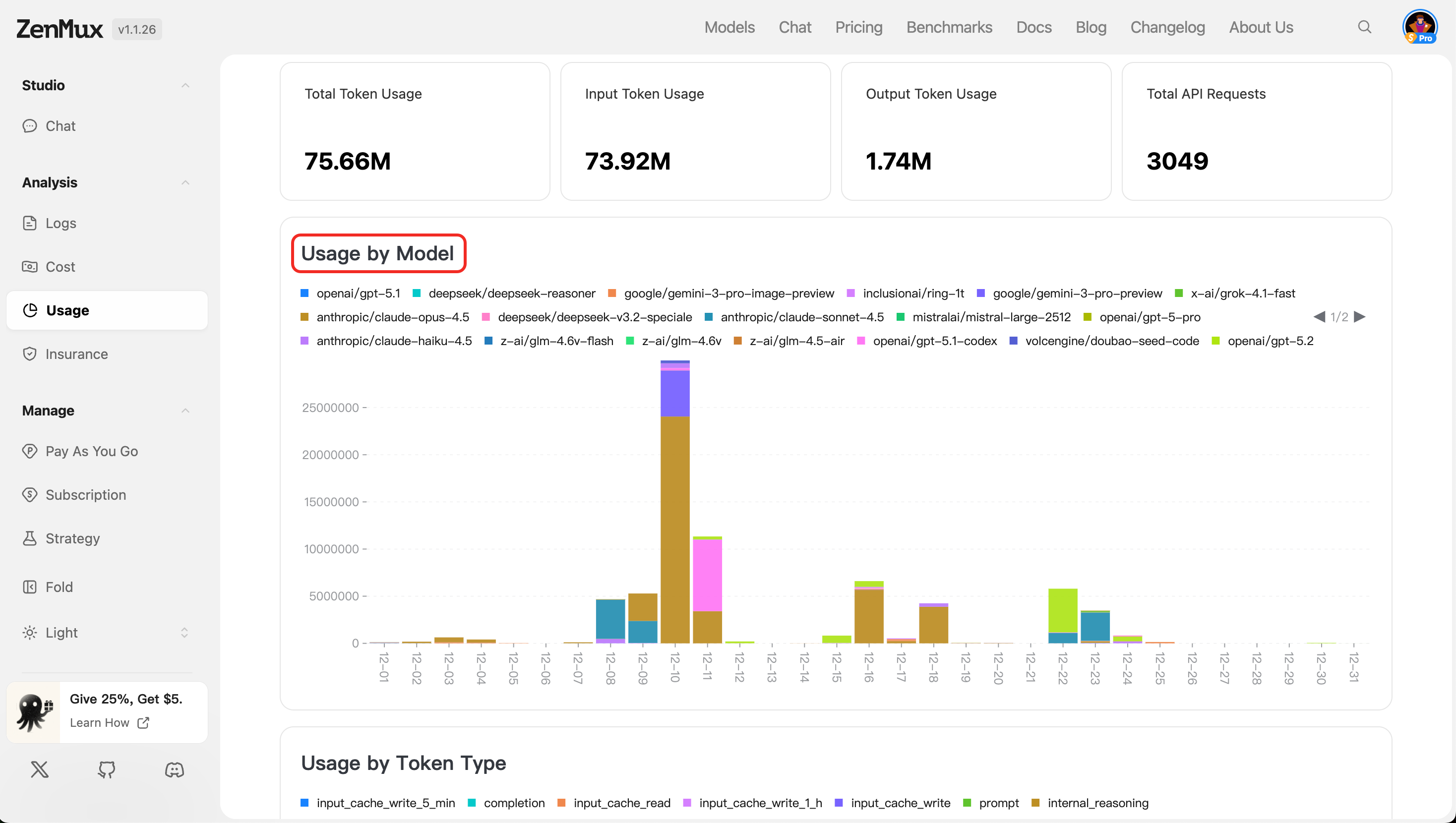
- 按类型分布(Usage by Token Type)
展示不同类型的Token使用分布情况。
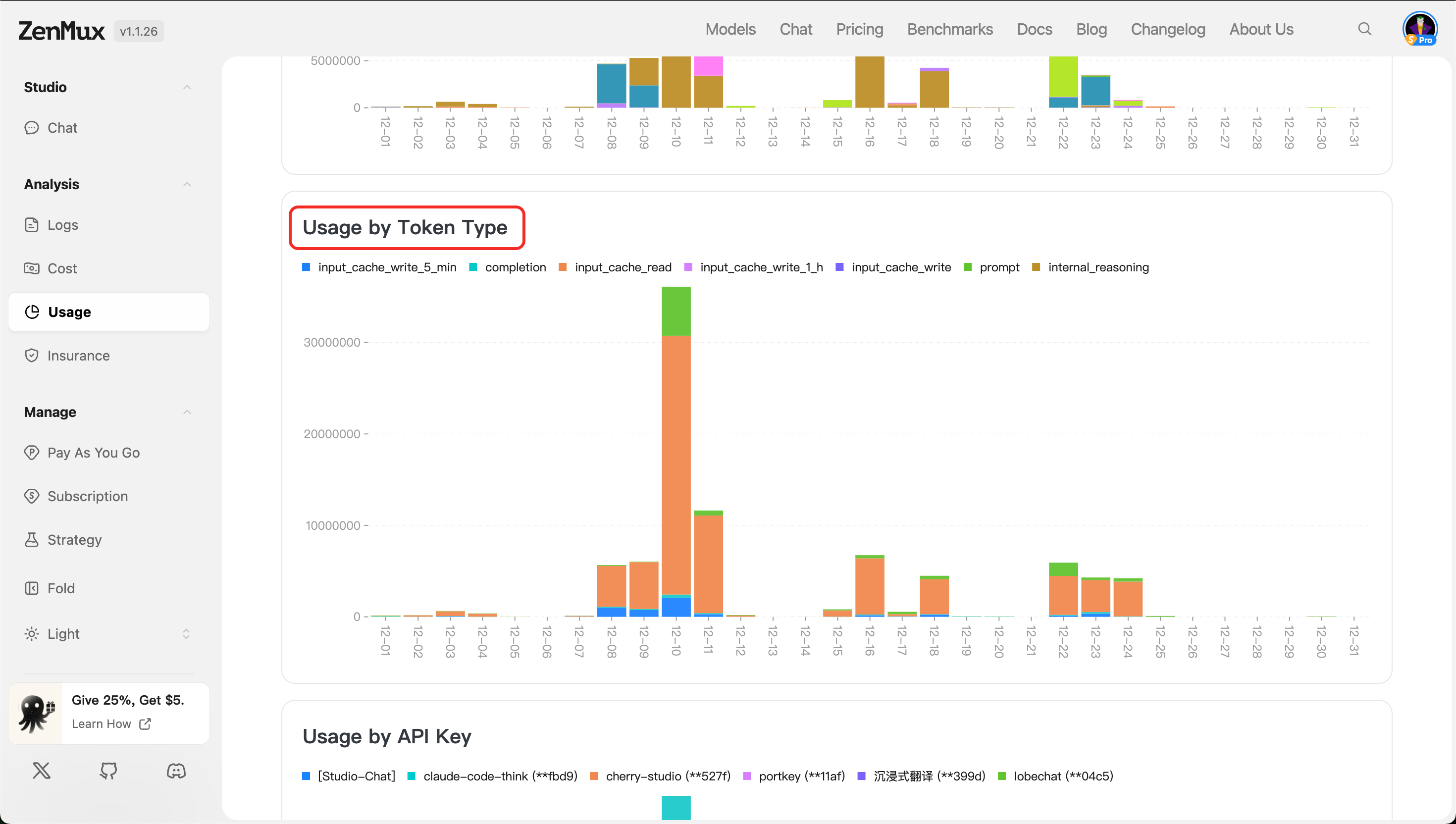
- 按 API Key 分布(Usage by API Key)
按不同 API 密钥维度展示 Token 和请求使用情况,适用于多用户或多项目场景下的用量隔离与审计。
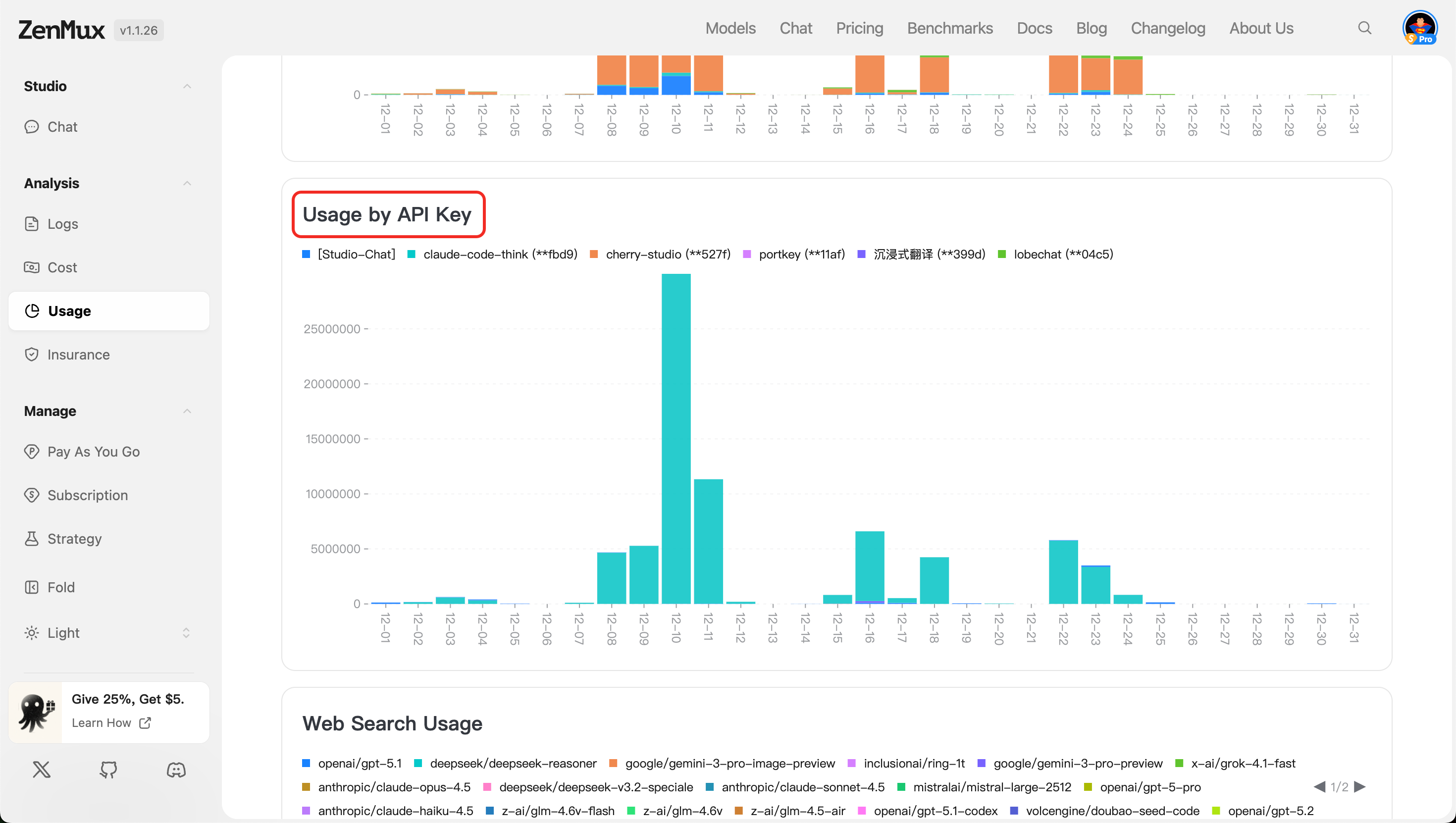
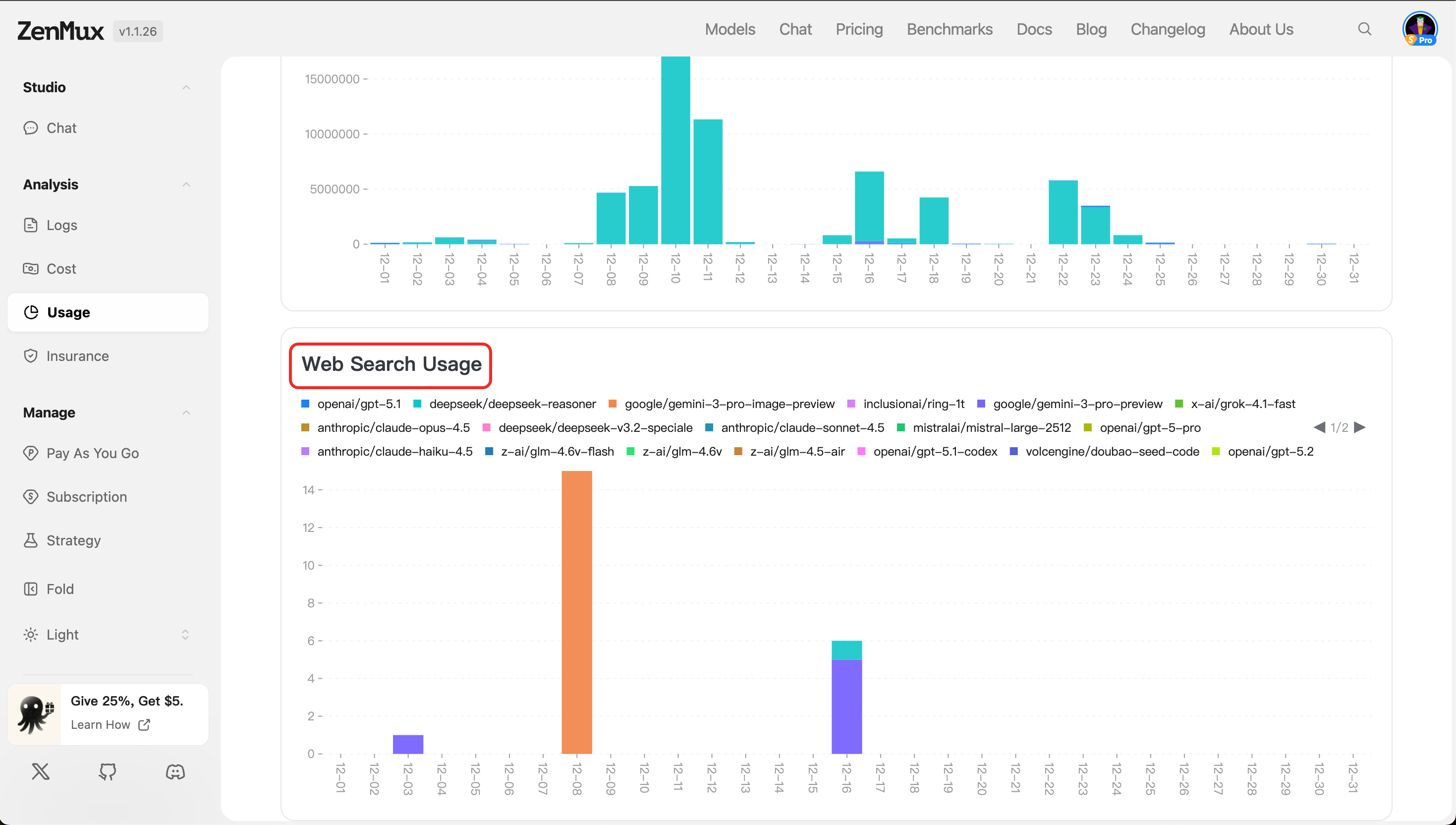
- 按Web搜索分布(Web Search Usage)
显示启用 Web 搜索功能的请求所消耗的 Token 量及调用次数(如适用),帮助评估增强检索功能的使用频率与开销。
服务提供商视图(Provider)
切换至“Provider”标签页,可查看不同 AI 服务提供商的使用表现。
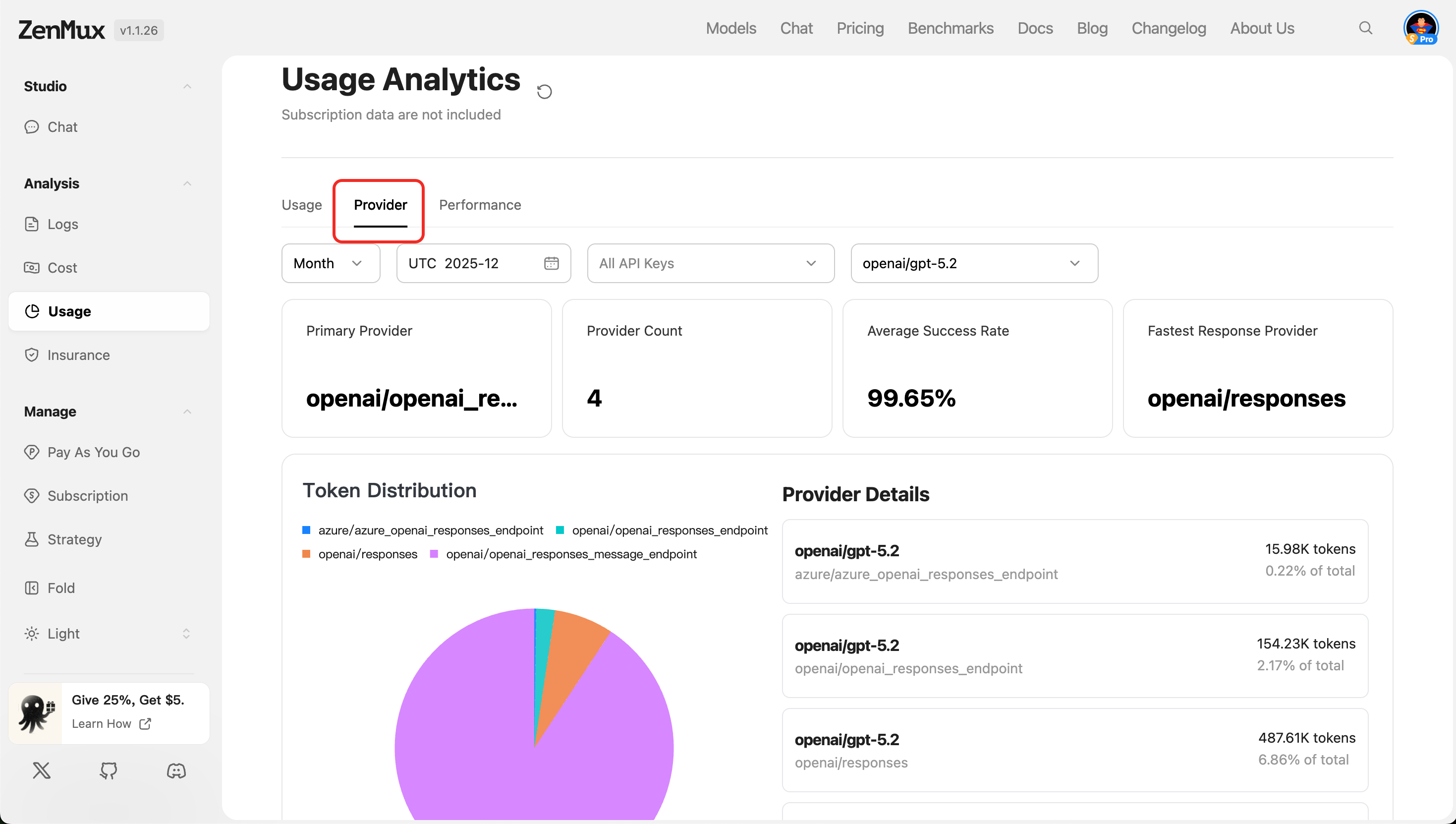
指标说明
| 指标 | 说明 |
|---|---|
| Primary Provider | 当前主要使用的 AI 服务提供商(如 Google Gemini、OpenAI 等)。 |
| Provider Count | 使用到的服务提供商总数。 |
| Average Success Rate | 所有请求的成功率平均值,反映服务稳定性。 |
| Fastest Response Provider | 响应时间最短的服务提供商。 |
各维度分析
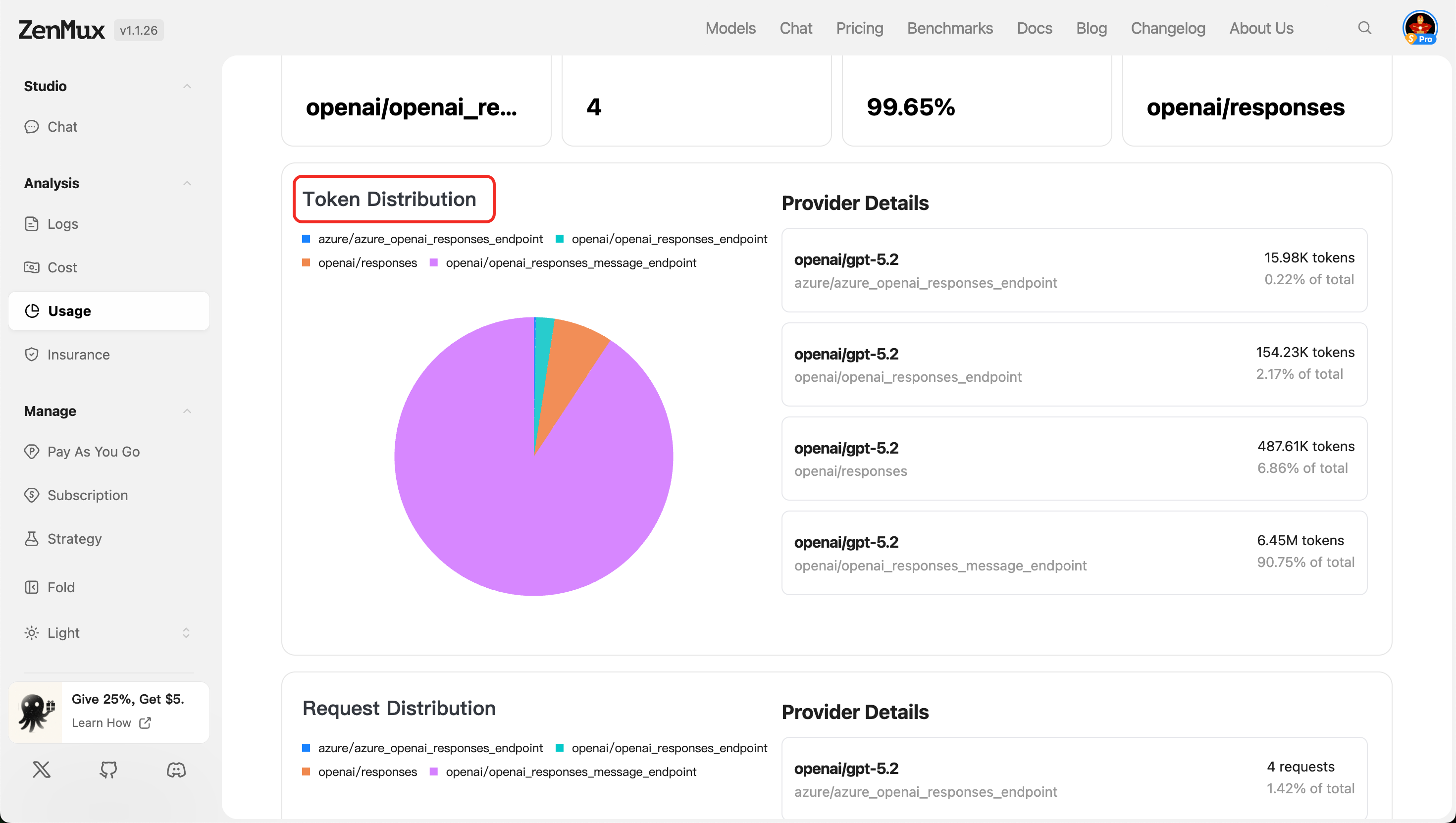
- Token Distribution
展示各提供商的 Token 使用占比,便于评估资源分配合理性。
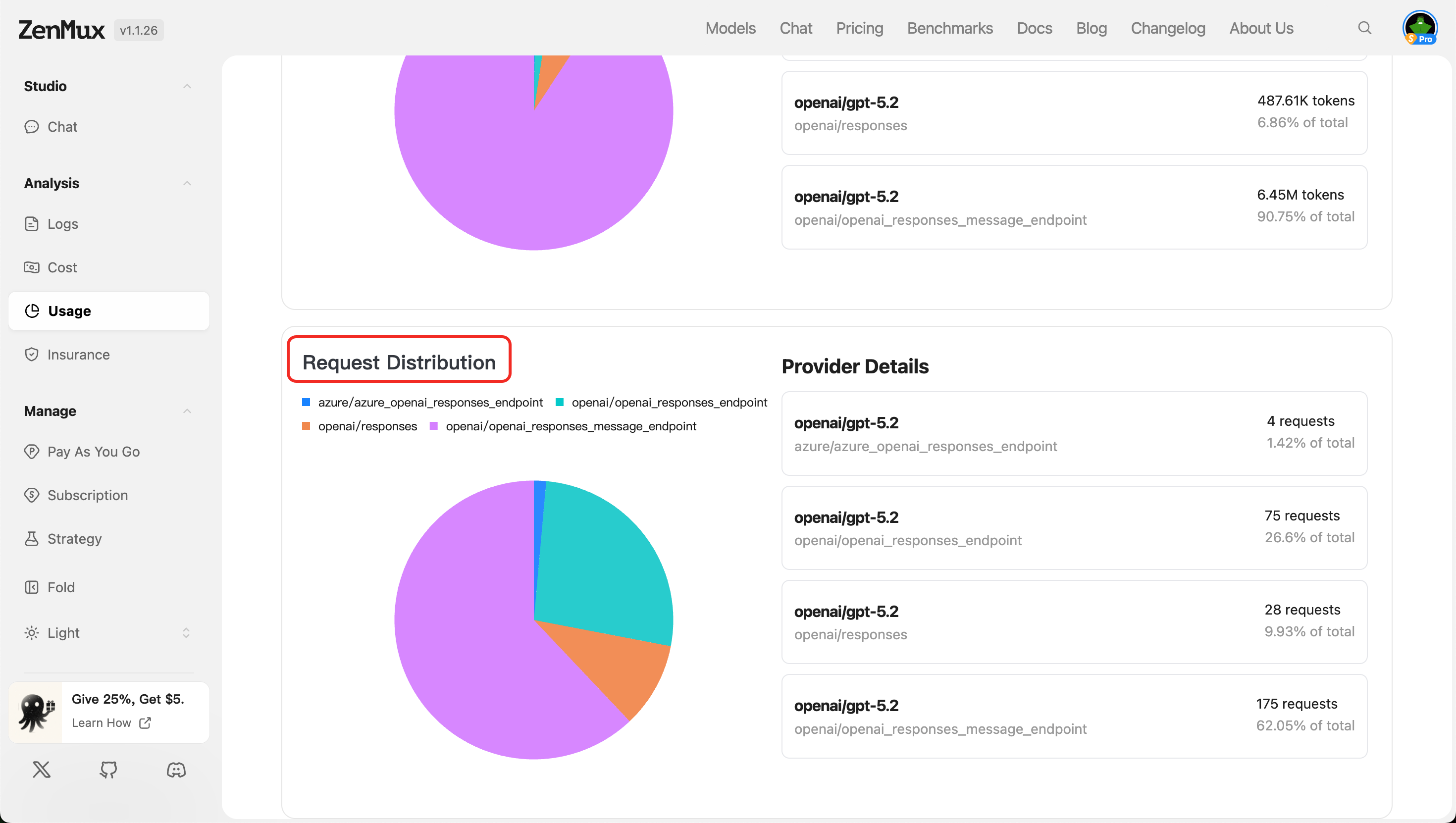
- Request Distribution
按服务提供商统计 API 请求次数分布,反映各提供商的调用负载情况。
提示:可结合模型与提供商筛选,深入分析特定组合的性能表现。
性能分析(Performance)
在“Performance”标签页中,您可以查看 API 调用的性能指标,用于评估模型响应效率与服务质量。
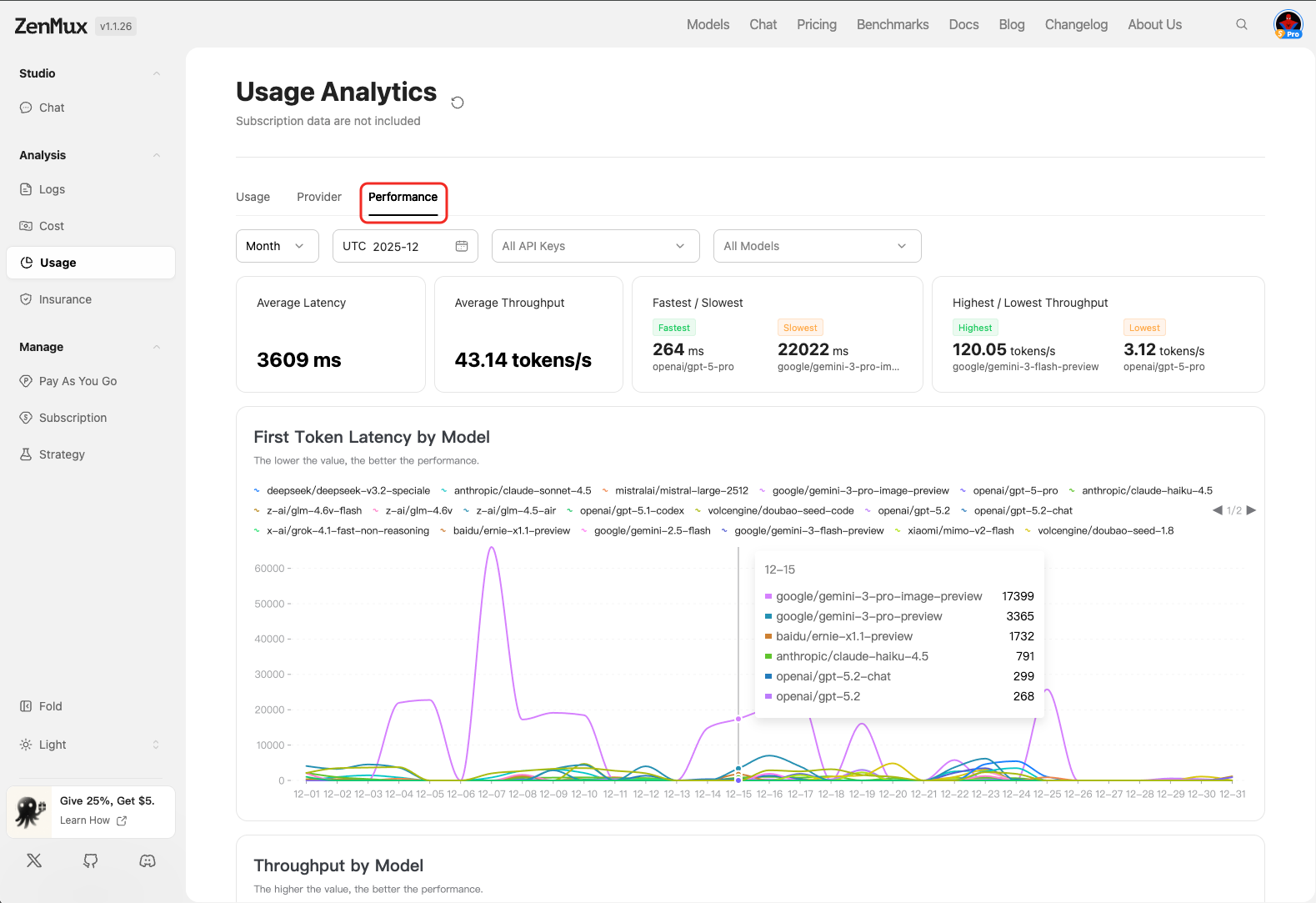
指标说明
| 指标 | 说明 |
|---|---|
| Average Latency | 平均响应延迟(毫秒),数值越低表示响应越快。 |
| Average Throughput | 平均吞吐量(Tokens/秒),反映单位时间内处理能力。 |
| Fastest / Slowest | 列出最快和最慢的模型响应记录,便于定位性能瓶颈。 |
| Highest / Lowest Throughput | 显示吞吐量最高和最低的模型,辅助优化负载均衡。 |
按模型分析
First Token Latency by Model
展示各模型生成首个 Token 的延迟时间。说明:首个 Token 的延迟是用户体验的关键指标,数值越小代表响应越迅速。
- 图表或列表形式展示不同模型的延迟分布。
- 支持按模型筛选,快速识别高延迟模型。
Throughput by Model
展示各模型的吞吐量(Tokens/秒)。说明:The higher the value, the better the performance.(数值越高,性能越好。)
- 用于横向比较不同模型在单位时间内的处理效率。
- 可辅助选择高吞吐模型以提升系统整体响应能力。
联系我们
如果您在使用过程中遇到任何问题,或有任何建议和反馈,欢迎通过以下方式联系我们:
- 官方网站:https://zenmux.ai
- 技术支持邮箱:[email protected]
- 商务合作邮箱:[email protected]
- Twitter:@ZenMuxAI
- Discord 社区:http://discord.gg/vHZZzj84Bm
更多联系方式和详细信息,请访问我们的联系我们页面。