Provider Routing
ZenMux adopts a multi-provider architecture, integrating multiple providers for the same model and selecting the optimal provider through intelligent routing to ensure the best performance and availability. When calling large models via ZenMux, developers do not need to worry about the underlying provider selection logic—simply specify the model name.
Why a Multi-Provider Architecture
In enterprise AI applications, a single-provider architecture carries significant risks:
- Service interruption risk: Provider failures can halt your business
- Performance fluctuation: Latency and throughput vary widely across providers
- Cost optimization challenges: Lack of flexible provider selection mechanisms
- Geographic limitations: A single provider may not cover global markets
- Compliance requirements: Different regions have varying rules on data storage and processing
ZenMux’s multi-provider architecture fundamentally addresses these issues, providing enterprise-grade assurance for your AI applications.
Key Benefits
High Availability
When a provider experiences service issues or capacity shortfalls, ZenMux automatically switches to other available providers to ensure continuity, without manual intervention.
Assurance mechanisms:
- Real-time health checks: Continuously monitor all providers’ service status
- Intelligent failover: Millisecond-level switching to backup providers
- Seamless transitions: Failover without user impact
- Multi-level redundancy: 2–3 providers for mainstream models
For detailed failover and model fallback strategies, see the Model Fallback Documentation (/guide/advanced/fallback.html).
Performance Optimization
Providers perform differently across geographies and time windows. ZenMux uses intelligent routing to select the best provider for each request.
Performance advantages:
- Latency optimization: First token latency is a key factor in provider selection
- Throughput assurance: Dynamically adjust provider allocation under high load
- Global acceleration: Leverage Cloudflare’s edge network for low global latency
- Real-time monitoring: Continuously track performance metrics to optimize routing
Flexible Cost Control
With a multi-provider architecture, you can flexibly select the most suitable provider based on budget and performance needs.
Cost optimization methods:
- Transparent price comparison: Real-time display of each provider’s pricing
- Easy switching: Seamlessly switch providers to optimize cost
- Demand-based routing: Control costs via provider routing configuration
Default Routing Strategy
ZenMux uses the following default routing strategy:
Intelligent Routing Principles
- Performance first: Sort by first token latency from low to high
- Smart switching: If the origin provider is unavailable, automatically switch to other providers
This approach ensures performance while maximizing service availability.
A Simple Way to Specify Providers
ZenMux offers a straightforward provider configuration—model name suffix syntax. You do not need a separate provider field; you can specify the provider directly in the model name.
Syntax
model_slug:provider_slugExamples
Model Slug Lookup
Each model on ZenMux has a unique slug. You can find the slug on the Model List page (https://zenmux.ai/models):  Or on a specific model’s detail page (https://zenmux.ai/anthropic/claude-sonnet-4.5):
Or on a specific model’s detail page (https://zenmux.ai/anthropic/claude-sonnet-4.5): 
Provider Slug Lookup
Model providers on ZenMux have unique slugs. You can find a model’s provider slug on the model’s detail page (https://zenmux.ai/anthropic/claude-sonnet-4.5): 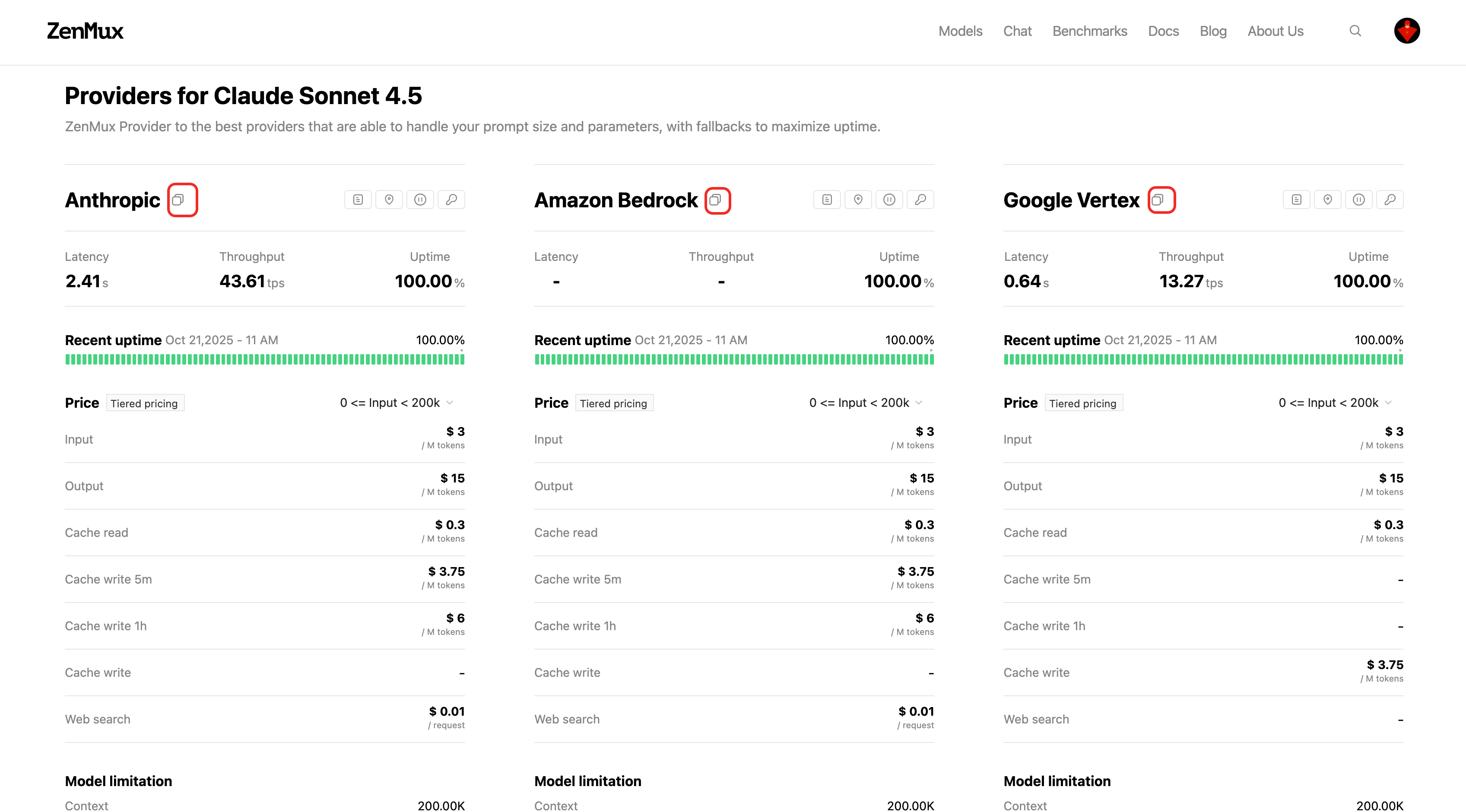
For example, to pin Claude 3.7 Sonnet to the AWS Bedrock provider, use:
anthropic/claude-3.7-sonnet:amazon-bedrockThe :amazon-bedrock suffix tells ZenMux to route the request specifically to the designated provider, with no extra configuration.
{
"model": "anthropic/claude-3.7-sonnet:amazon-bedrock",
"messages": [
{
"role": "user",
"content": "Hello, Claude!"
}
]
}from openai import OpenAI
client = OpenAI(
base_url="https://zenmux.ai/api/v1",
api_key="<your_api_key>"
)
response = client.chat.completions.create(
model="anthropic/claude-3.7-sonnet:amazon-bedrock",
messages=[
{"role": "user", "content": "Hello, Claude!"}
]
)
print(response.choices[0].message.content)Highlights
| Feature | Description |
|---|---|
| Simple & intuitive | Specify in the model name; no extra fields needed |
| API compatible | Fully compatible with the standard OpenAI SDK parameters |
| Fast switching | Switch providers by changing only the model name |
| Clear visibility | Instantly see which provider is being used |
💡 Best Practices
For most scenarios, we recommend using the model name suffix syntax to specify providers—it’s the simplest and most direct approach. If you need more complex routing (e.g., multi-provider fallback, dynamic priorities), use the advanced routing configuration below.
Advanced Routing Configuration
For finer control, ZenMux provides full provider configuration capabilities.
Route by Performance Metrics
Use provider.routing to sort providers by specific performance dimensions.
Supported Dimensions
| Dimension | Description |
|---|---|
| latency | Sort by first token latency from low to high |
| price | Sort by combined price (Prompt + Completion) from low to high |
| throughput | Sort by throughput from high to low |
Configuration Examples
{
"model": "anthropic/claude-sonnet-4",
"messages": [
{
"role": "user",
"content": "Hello!"
}
],
"provider": {
"routing": {
"type": "priority",
"primary_factor": "latency"
}
}
}{
"model": "anthropic/claude-sonnet-4",
"messages": [
{
"role": "user",
"content": "Hello!"
}
],
"provider": {
"routing": {
"type": "priority",
"primary_factor": "price"
}
}
}{
"model": "anthropic/claude-sonnet-4",
"messages": [
{
"role": "user",
"content": "Hello!"
}
],
"provider": {
"routing": {
"type": "priority",
"primary_factor": "throughput"
}
}
}Specify Provider List
You can explicitly set the provider list and call order to implement custom fallback behavior.
{
"model": "anthropic/claude-sonnet-4",
"messages": [
{
"role": "user",
"content": "Hello!"
}
],
"provider": {
"routing": {
"type": "order",
"providers": [
"anthropic/anthropic_endpoint",
"google-vertex/VertexAIAnthropic",
"amazon-bedrock/BedrockAnthropic"
]
}
}
}from openai import OpenAI
client = OpenAI(
base_url="https://zenmux.ai/api/v1",
api_key="<your_api_key>"
)
response = client.chat.completions.create(
model="anthropic/claude-sonnet-4",
messages=[
{"role": "user", "content": "Hello!"}
],
extra_body={
"provider": {
"routing": {
"type": "order",
"providers": [
"anthropic/anthropic_endpoint",
"google-vertex/VertexAIAnthropic",
"amazon-bedrock/BedrockAnthropic"
]
}
}
}
)Routing Behavior
When you specify a providers list, ZenMux behaves as follows:
- Sequential calls: Attempt providers in listed order
- Stop on success: Stop once any provider returns successfully
- Single provider: If only one provider is specified, ZenMux will call only that provider
- Error handling: If the specified provider returns an error, return that error directly
⚠️ Cautions
When using custom routing strategies, ensure that the specified providers actually support the selected model; otherwise, calls may fail.
Use Cases
Different routing strategies fit different business scenarios:
| Scenario | Recommended Approach | Description |
|---|---|---|
| Pin a single provider | Model name suffix syntax | Simple and direct; suitable for production with fixed providers |
| Geographic optimization | Specify provider list | Choose geographically closer providers to reduce latency |
| Cost control | Route by price | Prefer providers with better pricing |
| Performance optimization | Route by latency or throughput | Dynamically select the best provider based on performance metrics |
| High availability | Specify multiple providers | Multi-provider fallback to ensure continuity |
| Compliance requirements | Pin specific providers | Choose providers that meet data compliance requirements |
| Testing & validation | Flexible switching | A/B test provider performance |
📋 Complete Example
import requests
# Example 1: Use model name suffix syntax (recommended)
response_1 = requests.post(
"https://zenmux.ai/api/v1/chat/completions",
headers={
"Authorization": "Bearer <your_api_key>",
"Content-Type": "application/json"
},
json={
"model": "anthropic/claude-sonnet-4:anthropic",
"messages": [{"role": "user", "content": "Hello!"}]
}
)
# Example 2: Use advanced routing configuration
response_2 = requests.post(
"https://zenmux.ai/api/v1/chat/completions",
headers={
"Authorization": "Bearer <your_api_key>",
"Content-Type": "application/json"
},
json={
"model": "anthropic/claude-sonnet-4",
"messages": [{"role": "user", "content": "Hello!"}],
"provider": {
"routing": {
"type": "order",
"providers": [
"anthropic/anthropic_endpoint",
"amazon-bedrock/BedrockAnthropic"
]
}
}
}
)
print(response_1.json())
print(response_2.json())By properly configuring provider routing strategies, you can optimize API call performance, cost, and reliability based on your specific business needs.
How to View Provider Information
Model Details Page
Click any model card to open its detail page, where you can view:
- Provider list: All providers supported by the model
- Performance comparison: First token latency, throughput, and other metrics across providers
- Price comparison: Detailed pricing for all billing items across providers
- Parameter comparison: Parameters supported by each provider
- Supported protocols: Call protocols supported by each provider (OpenAI API, Anthropic API, etc.)
- Availability status: Real-time service status of each provider
- Provider slug: Identifier used for provider routing configuration
Model Details Page Example
For example, at the Claude Sonnet 4 detail page (https://zenmux.ai/anthropic/claude-sonnet-4), you can see comprehensive comparisons across providers such as Anthropic, Google Vertex, and Amazon Bedrock.
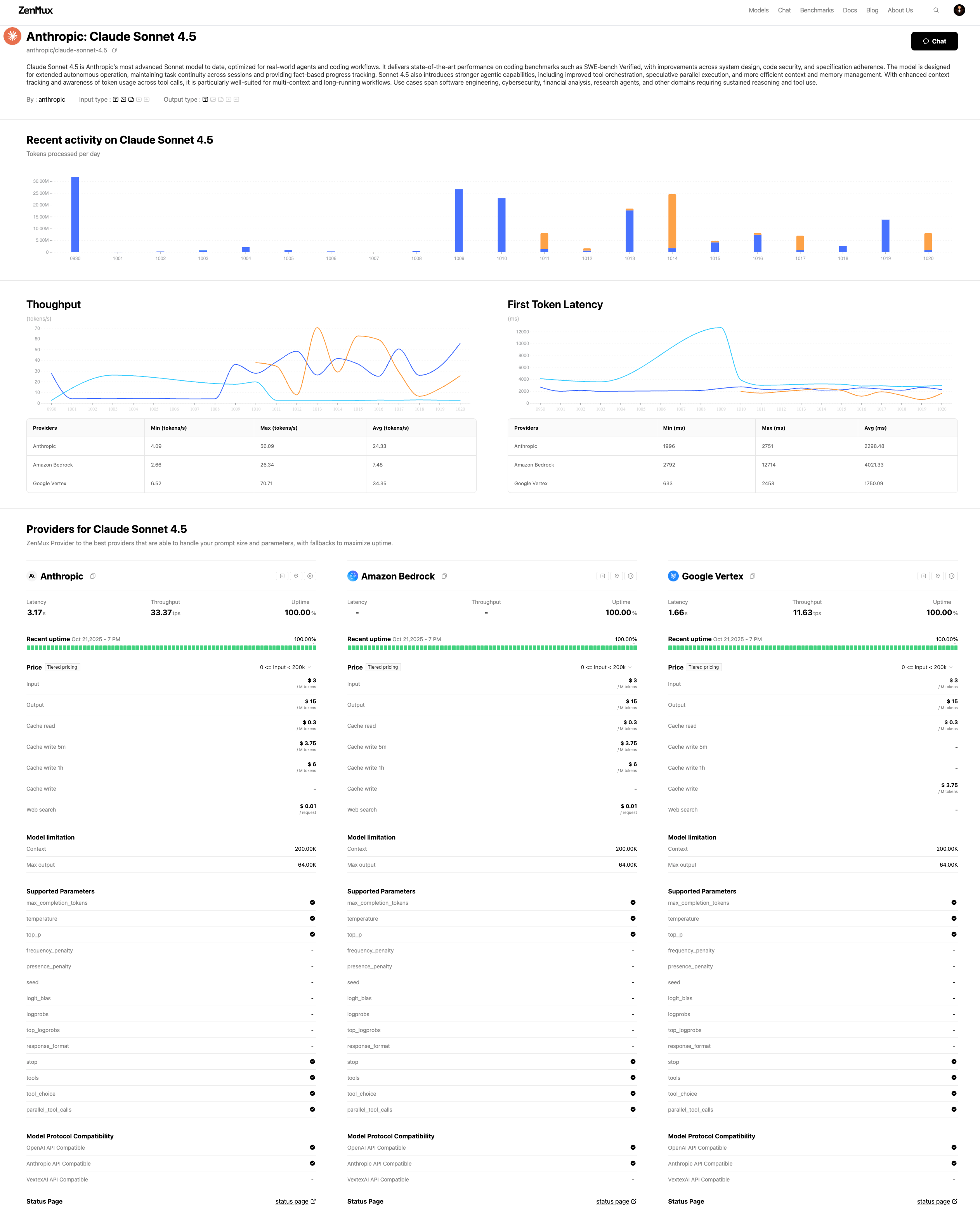
Provider Details Page
You can also view all models supported by a provider on the provider details page:
- Model list: All models integrated by the provider
- Usage statistics: Usage data across all models integrated by that provider
Provider Details Page Example
For example, visit the Anthropic provider page (https://zenmux.ai/providers/anthropic) to see all Claude models provided by that provider and their details.
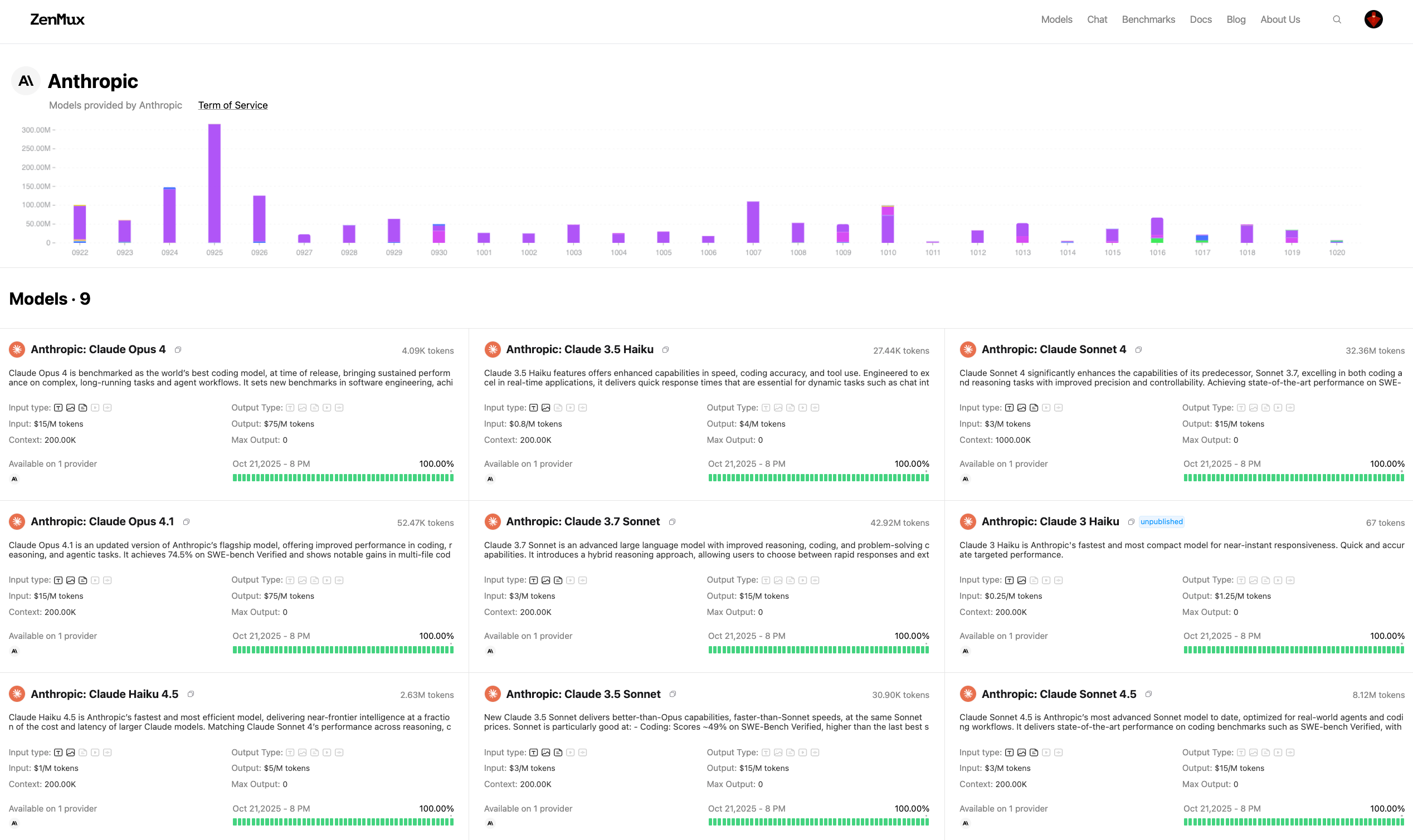
Through the model and provider detail pages, you can comprehensively understand the characteristics of each model and provider and make the best choice for your business needs.
FAQ
Q: How can I see which provider was used for a specific call?
A: In the ZenMux Console (https://zenmux.ai/settings/activity), the request logs show detailed information for each request, including the model and provider used.
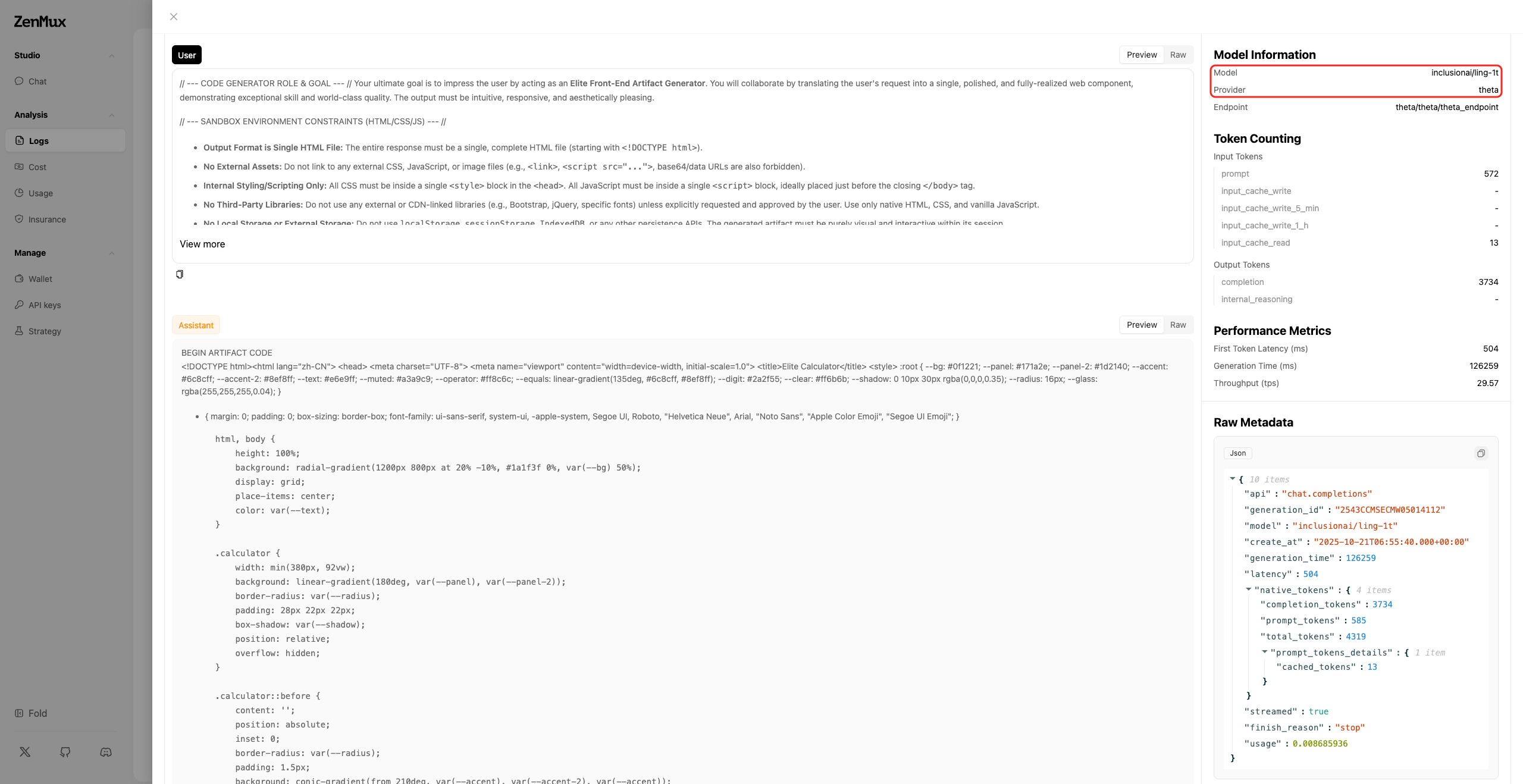
Q: Will automatic provider switching affect output consistency?
A: The same model across different providers usually produces consistent outputs because they use the same underlying model weights. Some providers may have minor response time differences.
Q: Does the multi-provider architecture increase latency?
A: No. ZenMux’s routing decisions are made at millisecond scale, with negligible impact on overall latency. In fact, by intelligently selecting low-latency providers, it can reduce total response time.
Contact Us
If you encounter any issues during use or have suggestions and feedback, feel free to contact us:
- Official website: https://zenmux.ai
- Technical support email: [email protected]
- Business cooperation email: [email protected]
- Twitter: @ZenMuxAI
- Discord community: http://discord.gg/vHZZzj84Bm
For more contact methods and details, please visit our Contact Us page (/help/contact).